Your Neuron Is a Picture, in JAX/Flax NNX
#ml#kernels#interpretability#mlp#yat#prototypes#jax#flax#nnx#implementation#deep-learning
The explainer argued that a neuron storing a direction can never be pointed at, while a neuron storing a prototype is a thing you can look at, and on images that thing is a picture. This is the implementation companion: build the prototype MLP in Flax NNX, train it on Fashion-MNIST, and then actually look at the neurons. Every figure and number below is from a real run.
The network, with no activation function
A Yat unit measures the input against a learned prototype with the kernel . A layer is a bank of them, and there is no activation function. The whole model is that layer plus a linear readout.
import jax, jax.numpy as jnp
from flax import nnx
class YatLayer(nnx.Module):
"""A bank of prototypes. Each unit is a kernel against a point in input space."""
def __init__(self, d_in, n_units, *, rngs: nnx.Rngs, Winit, b0=1.0, eps0=1.0):
self.W = nnx.Param(jnp.asarray(Winit)) # [n_units, d_in] prototypes
self.log_b = nnx.Param(jnp.full((), jnp.log(jnp.expm1(b0))))
self.log_eps = nnx.Param(jnp.full((), jnp.log(jnp.expm1(eps0))))
def __call__(self, x):
b, eps = jax.nn.softplus(self.log_b.value), jax.nn.softplus(self.log_eps.value)
dot = x @ self.W.value.T
dist2 = jnp.sum(x ** 2, -1, keepdims=True) + jnp.sum(self.W.value ** 2, -1) - 2 * dot
return (dot + b) ** 2 / (dist2 + eps)
class YatMLP(nnx.Module):
def __init__(self, d_in, n_units, d_out, *, rngs: nnx.Rngs, Winit):
self.yat = YatLayer(d_in, n_units, rngs=rngs, Winit=Winit)
self.readout = nnx.Linear(n_units, d_out, rngs=rngs)
def __call__(self, x):
return self.readout(self.yat(x)) # kernel votes -> logitsThe entire nonlinearity of the network is in that one expression, and it has exactly two learnable scalars: a numerator bias b and a denominator floor ε. They are stored as log_b and log_eps and pushed through softplus, which is the whole reason the layer cannot break: no matter what gradient descent does to the raw parameters, b and ε stay non-negative.
The prototypes are parameters, so they need initial values. We seed them from random training images, which both starts them legible and, as we will see, lets us watch them move.
import numpy as np, torchvision
tr = torchvision.datasets.FashionMNIST("/tmp/fmnist", train=True, download=True)
te = torchvision.datasets.FashionMNIST("/tmp/fmnist", train=False, download=True)
X = tr.data.numpy().reshape(-1, 784).astype("float32") / 255.0; y = tr.targets.numpy()
Xte = te.data.numpy().reshape(-1, 784).astype("float32") / 255.0; yte = te.targets.numpy()
X, y = X[:20000], y[:20000] # a subset, for speed
K = 48
Winit = X[np.random.RandomState(1).permutation(len(X))[:K]] # K random training imagesBuild it without training first
Before training anything, notice what the architecture already is. A Yat unit votes by resemblance to its prototype, so if you set the prototypes to labeled images and hard-wire the readout to one-hot, , the prediction becomes
each prototype casting its resemblance as a vote for its own class. This is Nadaraya–Watson with a hard label per prototype: a working classifier with zero gradient steps, and the kernel machine the whole model is built around.
from sklearn.cluster import KMeans
def build_by_hand(per_class):
W, lab = [], []
for c in range(10): # prototypes = k-means centroids of each class
cen = KMeans(per_class, n_init=3, random_state=0).fit(X[y == c][:2500]).cluster_centers_
W += list(cen); lab += [c] * per_class
A = jnp.asarray(np.eye(10)[lab]) # readout: each prototype votes for its class
return jnp.asarray(np.array(W)), A, np.array(lab)
def yat_kernel(W, x, b=0.5, eps=0.05): # activations, inputs × prototypes
dot = x @ W.T
return (dot + b) ** 2 / (jnp.sum(x**2, -1, keepdims=True) + jnp.sum(W**2, -1) - 2 * dot + eps)
W, A, lab = build_by_hand(per_class=20)
votes = yat_kernel(W, jnp.asarray(Xte)) @ A # linear readout = sum of class votes
print("zero-training accuracy:", round(float((votes.argmax(-1) == yte).mean()) * 100, 1)) # ~68%Sixty-eight percent on Fashion-MNIST, no optimizer, no backprop. (The linear readout can only sum the votes, which the Yat kernel’s non-decaying tail caps around 68%; replacing the sum with a nearest-prototype max reaches ~79%, but a linear layer cannot express a max.) The point stands: classification is not something training installs in a black box. It is what the architecture is, and a good engineered selection of prototypes makes it work on its own. Clean centroids beat quantity here, fifty centroids outscore two thousand random exemplars.
Add the prototypes one at a time and you can watch the classifier resolve, with no training at any point.
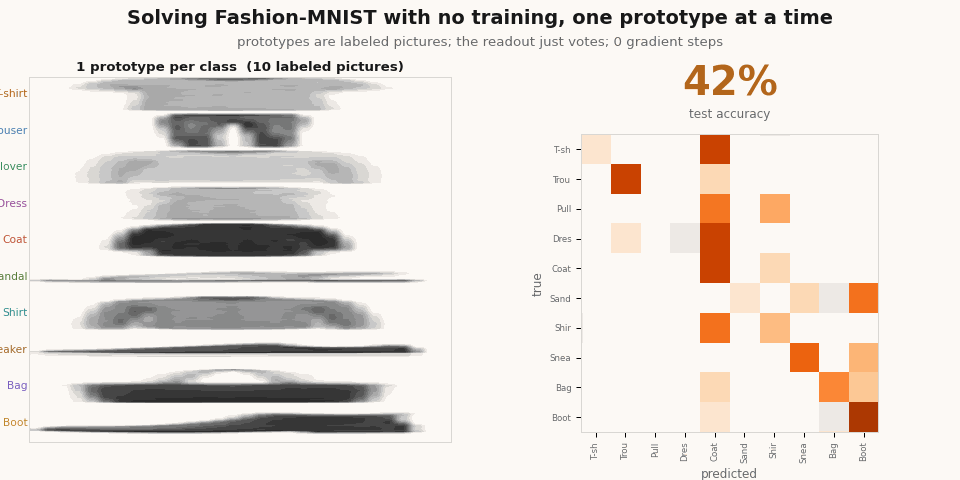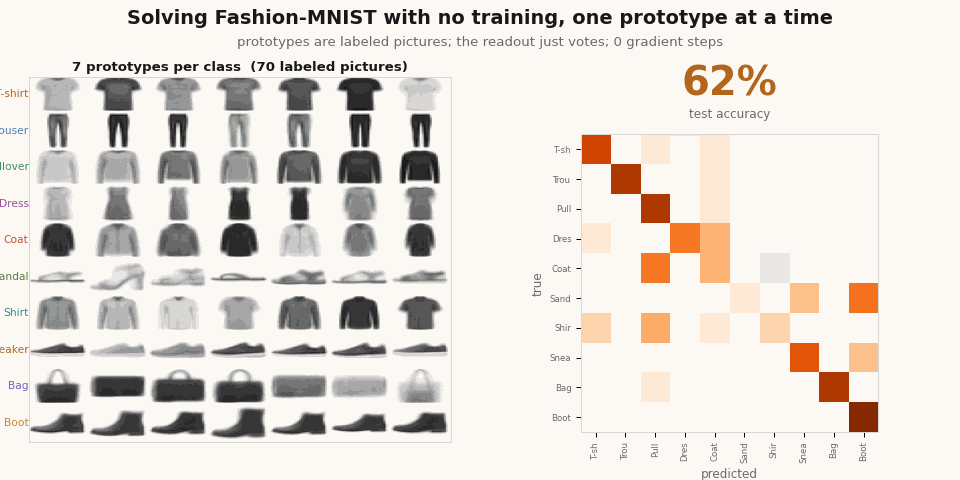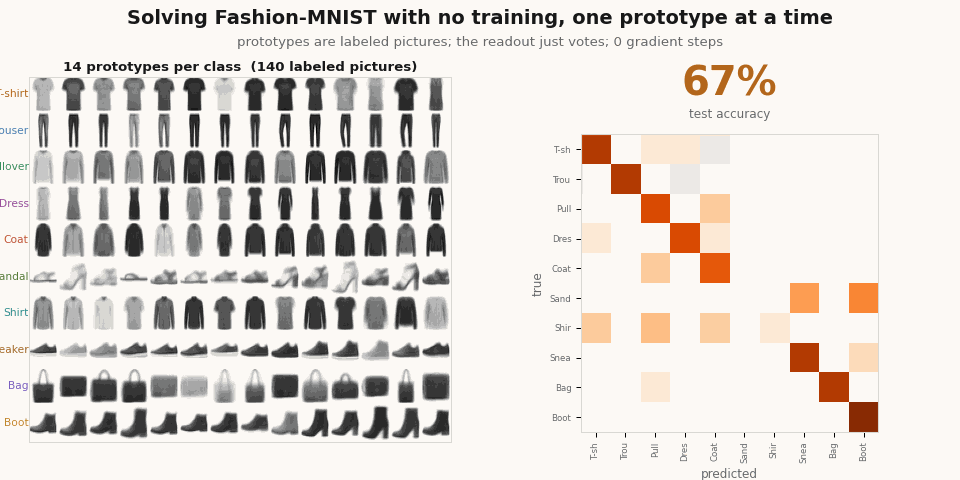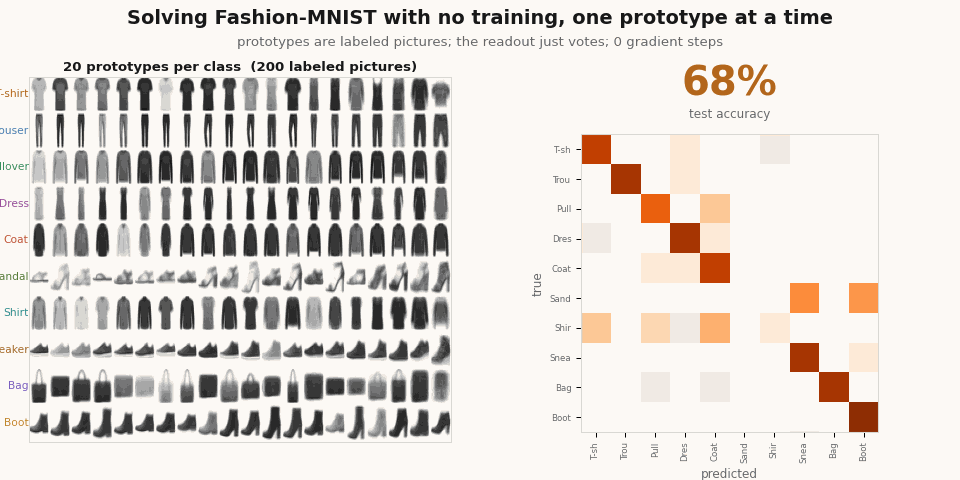
scripts/render_yat_notrain_gif.py.Now train it to sharpen it
Training does not create that ability; it sharpens it. Gradient descent adjusts the prototypes and learns a smarter readout than one-hot, carrying the hand-built 68% up toward 85%. (The centroids above were for the hand-built classifier; from here we train the model defined earlier, seeded from random images, which both stays legible and lets us watch the prototypes move later.) It trains like any NNX module, and the only nonlinearity in the network is still the kernel.
import optax
model = YatMLP(784, K, 10, rngs=nnx.Rngs(0), Winit=Winit)
opt = nnx.Optimizer(model, optax.adam(4e-3), wrt=nnx.Param)
@nnx.jit
def train_step(model, opt, xb, yb):
def loss_fn(model):
return optax.softmax_cross_entropy_with_integer_labels(model(xb), yb).mean()
loss, grads = nnx.value_and_grad(loss_fn)(model)
opt.update(model, grads)
return loss
B = 256
for epoch in range(12):
perm = np.random.RandomState(epoch).permutation(len(X))
for i in range(0, len(X) - B, B):
j = perm[i:i + B]
train_step(model, opt, jnp.asarray(X[j]), jnp.asarray(y[j]))
acc = float((jnp.argmax(model(jnp.asarray(Xte[:5000])), -1) == yte[:5000]).mean())
print("test accuracy:", round(acc * 100, 1)) # ~82.1%A same-shaped ReLU MLP (Linear -> relu -> Linear) trained the same way reaches about 84.5%. A couple of points of accuracy is the whole cost of what follows.
There is a practical payoff to building the model before you train it. The hand-built network is a warm start: instead of Winit from random images and a random readout, seed the prototypes with build_by_hand centroids and set the readout to the one-hot A, then run the exact same training loop. This is most useful where black boxes are weakest. With only 40 images per class, the engineered model scores 65.5% with zero gradient steps and fine-tunes to 75.3%, versus 72.0% from a random start. And because you pick the prototypes, you can hand the rare classes extra votes: on a split where two classes are starved to 30 examples, warm-starting lifts their recall from 48% to 59% (mean over five runs) and overall accuracy with it. Gradient descent never has to discover that the rare classes exist; the one-hot readout says so on step zero, and training only refines the boundary.
The prototypes are the weights
There is nothing to decode. The hidden layer’s parameters are [K, 784], and each row reshaped to 28x28 is an image of a piece of clothing. The ReLU MLP’s first-layer weights have the same shape and reshape to noise. The reason is the representer theorem: a kernel does its work in an RKHS , but its parameters are the centers , which live in the input space , the same space the data lives in. model.yat.W.value is literally a stack of points in image space.
protos = np.asarray(model.yat.W.value) # [48, 784] the prototypes
assert protos.shape == (K, 784)
gallery = protos.reshape(K, 28, 28) # 48 pictures, no method required
relu_filters = np.asarray(relu_model.l1.kernel.value).T.reshape(K, 28, 28) # 48 noise tilesBecause we seeded the prototypes from training images, they are pictures from the first step, and the kernel keeps them that way as they adapt. The ReLU filters start from standard random init and never resolve into anything. That difference in starting point is the right thing to be suspicious of, and we pin it down below.
Read a prediction as a vote over pictures
Because the readout is linear over kernel activations, a prediction decomposes into similarity to prototypes, and each prototype is a picture you can show.
def explain(model, x): # x: [784]
act = model.yat(x[None])[0] # [K] kernel similarity to each prototype
logits = model.readout(act[None])[0]
pred = int(jnp.argmax(logits))
share = act / act.sum() # normalized contribution
top = jnp.argsort(-act)[:5] # the prototypes it most looks like
return pred, [(int(u), float(share[u])) for u in top]
pred, top = explain(model, jnp.asarray(Xte[0]))
print("prediction:", pred, "because it looks like prototypes:", top)There is no separate explainer object. The bars are the forward pass, and the things being compared are images.
It knows when it does not know
A Yat unit is peaked at its prototype, so an input far from every prototype evaluates small against all of them. Feed the clothing model MNIST digits and the strongest match collapses, which is a calibrated “I do not recognize this” that a ReLU MLP never gives.
def max_match(model, X):
return np.asarray(model.yat(jnp.asarray(X))).max(1)
mnist = torchvision.datasets.MNIST("/tmp/mnist", train=True, download=True)
Xood = mnist.data.numpy().reshape(-1, 784).astype("float32") / 255.0
print("Fashion max-match (median):", round(float(np.median(max_match(model, Xte[:2000]))), 1)) # ~230
print("MNIST max-match (median):", round(float(np.median(max_match(model, Xood[:2000]))), 1)) # ~26A ninefold gap: a digit looks like nothing in the wardrobe, so the model abstains instead of guessing.
Where the pictures come from
So the prototypes are pictures because we initialized them as pictures. Does the kernel deserve any of the credit, or is it all the initialization? The clean test is to give the same kernel a noise start and see what happens. To make it a fair fight, the noise is matched to the data’s own per-pixel mean and variance, so it differs from the images only in having no spatial structure.
mu, sd = X.mean(0), X.std(0) # the data's per-pixel statistics
Wnoise = np.clip(mu + sd * np.random.RandomState(1).randn(K, 784), 0, 1) # stats-matched noise, no structure
noisy = YatMLP(784, K, 10, rngs=nnx.Rngs(0), Winit=Wnoise.astype("float32"))
# ... train identically ...
# test accuracy ~84%, the same as the others; but noisy.yat.W reshaped to 28x28 stays noise.It classifies, and it never becomes legible. So the answer is: both matter, for different things. The kernel is what makes a prototype able to be a picture, since it stores a point in input space rather than a direction; but a noise point is still a point, and training does not pull it onto the data, so it stays noise. Seeding from data is what puts the prototype where the pictures are, and the kernel’s locality keeps it there. Train all three banks side by side and the dissociation is plain: two are kernels, all three classify, only the data-seeded one is readable.
Two checks worth doing, because the result invites them. It is not an artifact of a badly-scaled noise: the noise above already matches the data’s per-pixel mean and variance, and it still never resolves. And it is not undertraining: run the noise-seeded layer for ten times as many steps and its accuracy keeps climbing past the image-seeded run, while the average distance from each prototype to its nearest real image grows (from about 6 to 15, against a data-to-data nearest-neighbour floor of about 4.6). Training pushes a noise prototype further off the manifold, toward a discriminative but unreadable filter, not onto the data. The legibility is decided at initialization, by where you put the prototype, and nowhere else.
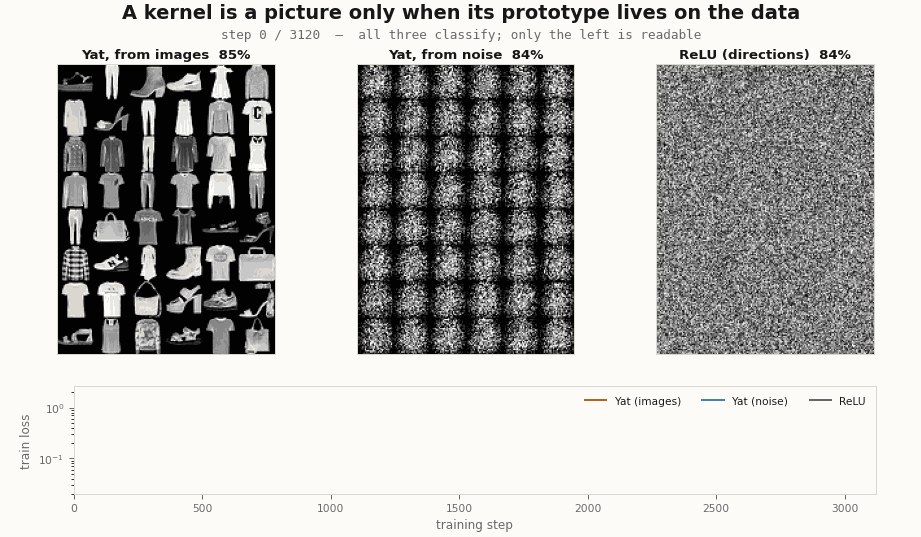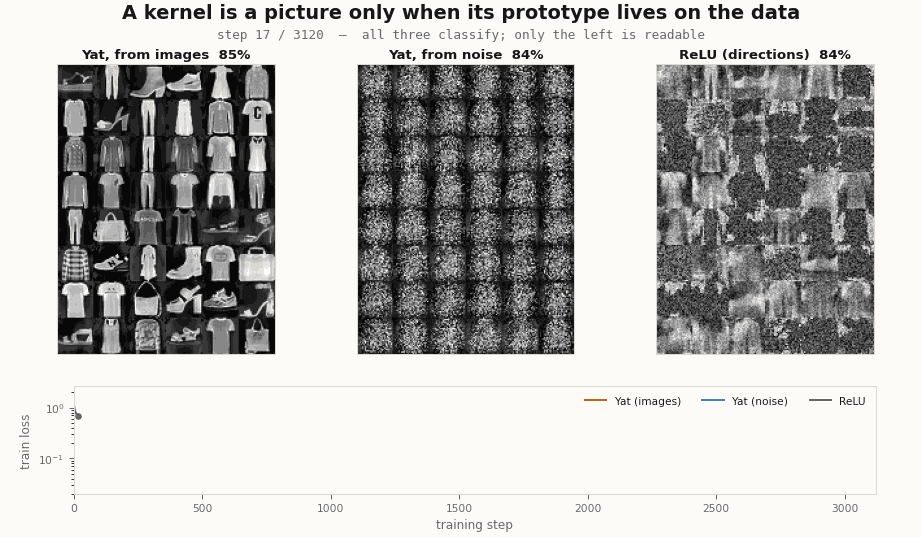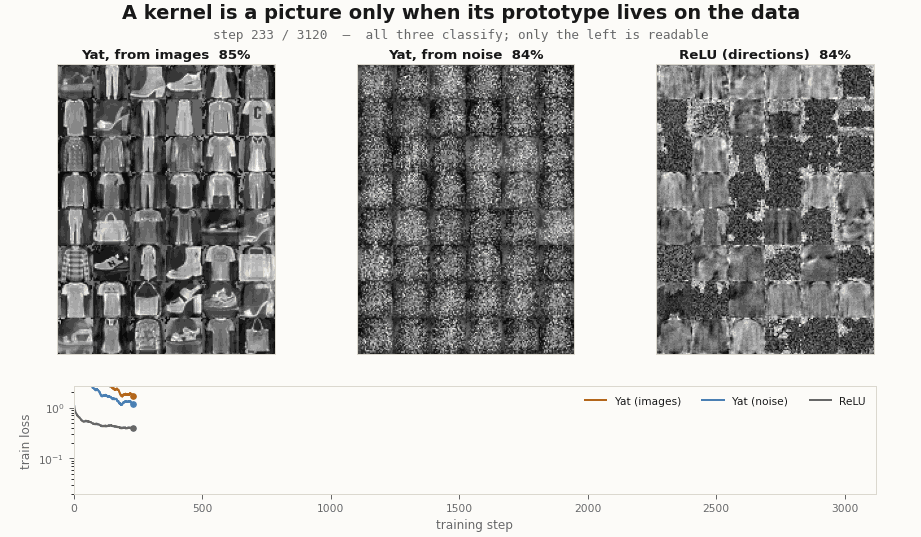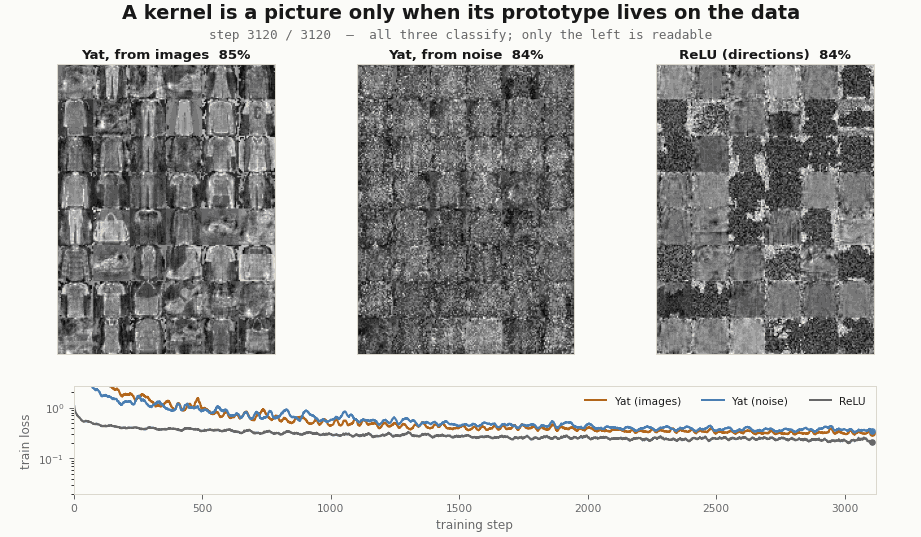
scripts/render_yat_fmnist_gifs.py.Watch the prototypes move through the data
Here is the part the explainer could only describe, and it doubles as the cleanest test of the “where the pictures come from” claim. The prototypes are points in the same 784-dimensional space as the images, so a dimensionality reduction fit on the dataset gives them a place on the same map, and UMAP can transform new points into a space it already learned. Snapshot the prototypes during training, project every snapshot into the data’s UMAP, and each prototype gets a trajectory.
import umap
sample = np.random.RandomState(5).permutation(len(X))[:3000]
reducer = umap.UMAP(n_neighbors=15, min_dist=0.25, random_state=42).fit(X[sample]) # learn the map on the data
data_xy = reducer.embedding_ # the Fashion-MNIST manifold in 2-D
traj_from_images = np.stack([reducer.transform(W) for W in image_snapshots]) # [snapshots, K, 2]
traj_from_noise = np.stack([reducer.transform(W) for W in noise_snapshots])A ReLU filter could not appear on this map at all: it is a direction, not a point in input space, so there is no place for it among the data. A prototype has a place, and where it goes depends entirely on where it started. Seed it from a training image and it migrates into the neighbourhood of the class it comes to detect. Seed it from noise and it never gets onto the manifold: it drifts into the empty gaps between the clusters and stays there, classifying without ever joining the data. The two panels are the same experiment as the gallery above, now in motion.

scripts/render_yat_fmnist_gifs.py.What this leaves out
One Yat layer on raw pixels at 82% is a teaching setup, not a benchmark. Put the kernel on top of learned features and a prototype becomes a feature-space exemplar, which is the ProtoPNet recipe (Chen et al., 2019); a clustering term sharpens the prototypes; width closes the accuracy gap. The trajectory view also depends on the prototypes being points in input space, which is exactly why it has no analogue for a direction. None of that changes the object: a layer whose unit stores a thing, so that on images the thing is a picture, and the network reads itself.
The prototype-network idea (“this looks like that”) is from Chen et al. (2019); UMAP from McInnes et al. (2018); Fashion-MNIST from Xiao et al. (2017); the Yat kernel from Bouhsine (2026). The conceptual companion is Your Neuron Is a Direction. It Should Be a Picture..
Cite as
Bouhsine, T. (). Your Neuron Is a Picture, in JAX/Flax NNX. Records of the !mmortal Data Scientist. https://tahabouhsine.com/blog/yat-mlp-fmnist-jax-flax-nnx/
BibTeX
@misc{bouhsine2026yatmlpfmnistjaxflaxnnx,
author = {Bouhsine, Taha},
title = {Your Neuron Is a Picture, in JAX/Flax NNX},
year = {2026},
month = {jun},
howpublished = {\url{https://tahabouhsine.com/blog/yat-mlp-fmnist-jax-flax-nnx/}},
note = {Blog post, Records of the !mmortal Data Scientist}
}References
- (2019). This Looks Like That: Deep Learning for Interpretable Image Recognition. NeurIPS 2019.arXiv:1806.10574
- (2018). UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv:1802.03426
- (2017). Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv:1708.07747
- (2026). A Universal Reproducing Kernel Hilbert Space from Polynomial Alignment and IMQ Distance. arXiv:2605.03262