LocalLLM Edge Server¶
An on-device, OpenAI-compatible LLM HTTP server for Android. Two
engines under one OpenAI Chat Completions API: Google's AICore (Gemini
Nano) via ML Kit GenAI on Pixel-class devices, and any LiteRT-LM
.litertlm bundle (Gemma 4 family + seven NPU-compiled Gemma 3 1B
SoC variants). No cloud, no remote API key, no data leaves the device.
Why this exists
Most apps already talk to LLMs over HTTP. The moment you move inference on-device, that contract breaks — every app embeds its own runtime, its own weights, its own engine. Three apps that each want a 2 GB model want 6 GB of RAM and three threads fighting for the same accelerator. This project is the one place on the device where LLMs actually run: apps keep speaking HTTP, the server owns the model lifecycle, queue, KV cache, rate limits, and metrics.
-
Open-API drop-in
Any OpenAI client library can talk to it. Streaming SSE,
session_id-based KV cache reuse, per-requesttemperature/top_k/max_tokens— all wire-compatible withPOST /v1/chat/completions. -
Two engines, one API
AICore (Gemini Nano) via
com.google.mlkit:genai-prompt:1.0.0-beta2is the default —gemini-nano-aicoreisSettings.DEFAULT_MODEL_ID. LiteRT-LM (com.google.ai.edge.litertlm:litertlm-android:0.12.0) is the alternative for offline weights, custom.litertlmbundles, or NPU-compiled SoC variants. Each catalog entry declares itsBackend(AICORE/LITERT_CPU/LITERT_GPU/LITERT_NPU) — no fallback chain.GET /healthexposes the live AICore status and the cached LiteRT engines. -
Production-leaning Android app
Foreground service with
specialUsedeclaration, SHA-256 download verification, signed-bearer-token API key, partial wake-lock under inference, idle-eviction of GB-sized engines, atomic queue cap with429 Retry-After, SSE error chunks (no silent drops). -
Hackable
~2k lines of Kotlin + Compose on top of Ktor 3. Single Gradle module, single test target, CI gating with GitHub Actions. New catalog entries are one struct + a SHA-256.
What it looks like¶
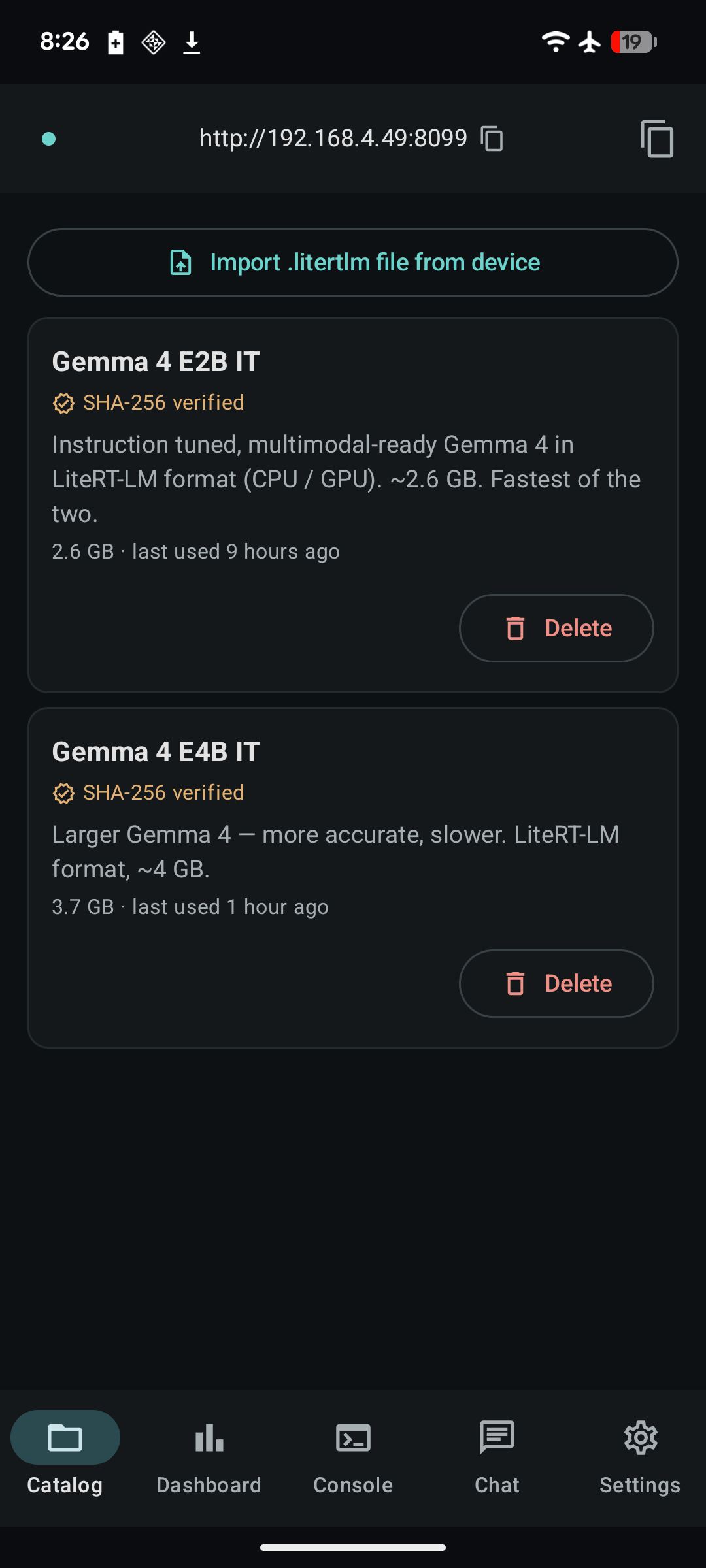
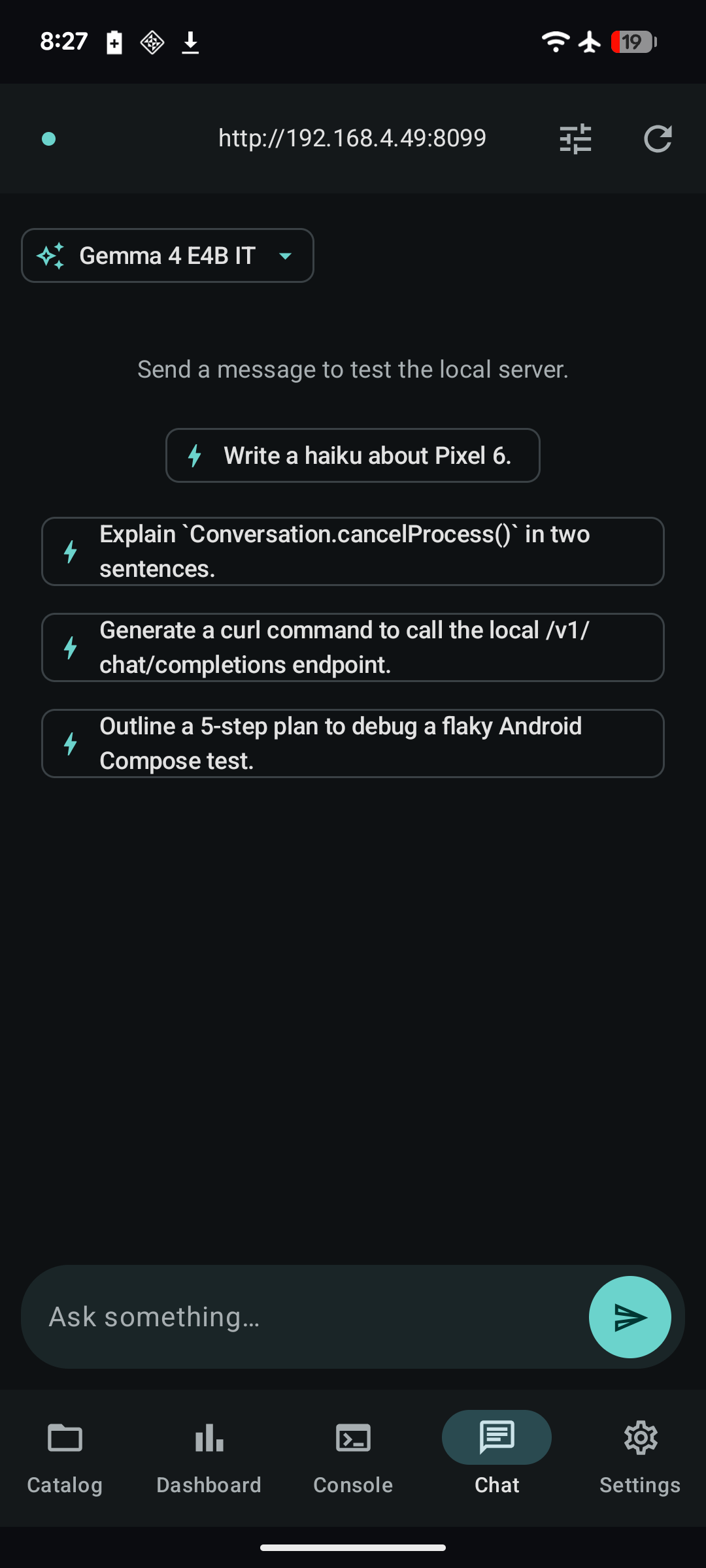
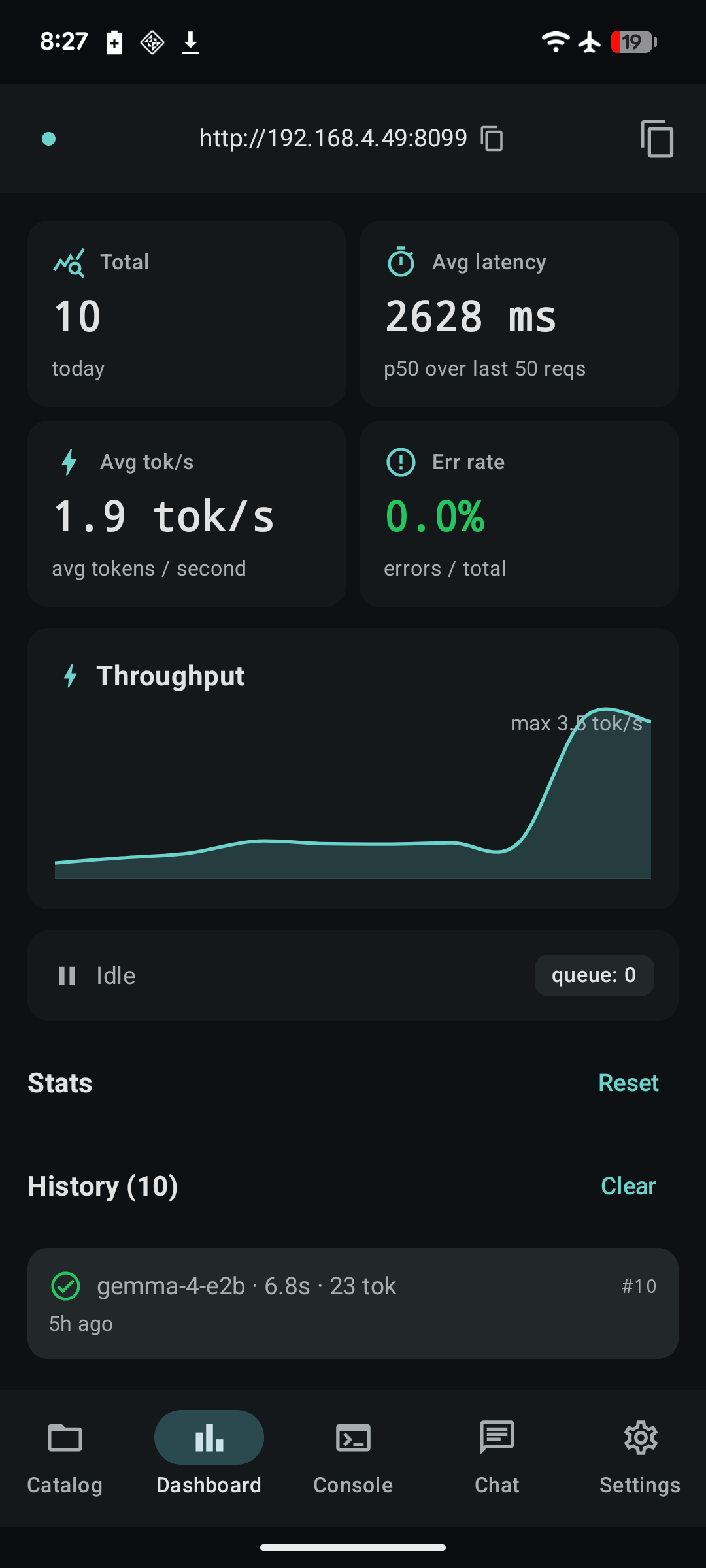
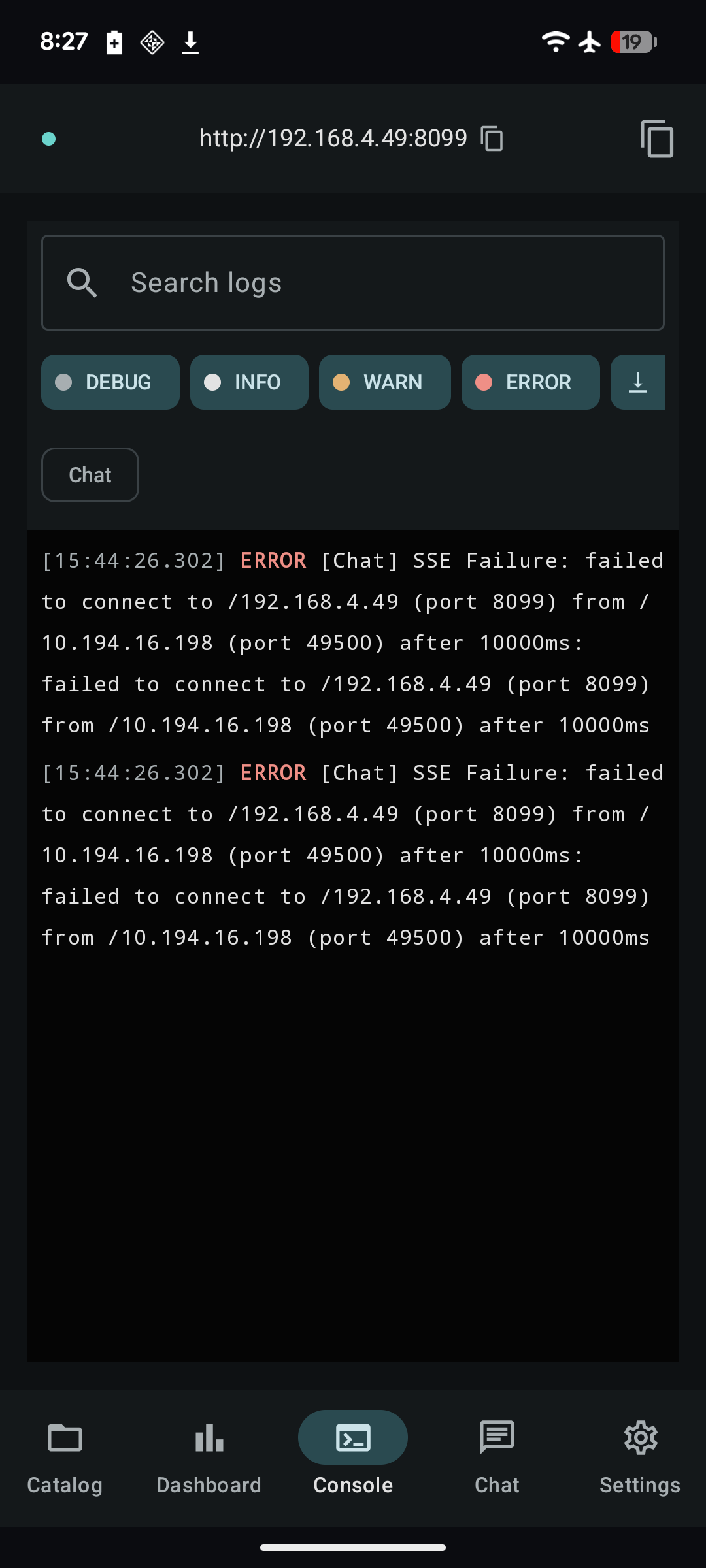
Quick demo¶
# 1. Install
adb install -r app-debug.apk
# 2. Forward the port to your laptop (or use the LAN IP from the app header)
adb forward tcp:8080 tcp:8080
# 3a. AICore (Gemini Nano) — no download, requires a supported Pixel.
# Keep the LocalLLM app in the foreground while the request is in
# flight (AICore returns ErrorCode 30 if backgrounded).
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-nano-aicore",
"messages": [{"role": "user", "content": "Say hi in one word."}]
}'
# 3b. Or, after tapping "Download" on Gemma 4 E2B IT (~2.6 GB) in the
# Catalog tab, use the LiteRT-LM path — no foreground constraint.
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gemma-4-e2b",
"messages": [{"role": "user", "content": "Say hi in one word."}]
}'
Why this exists¶
There's no public Android library that exposes Gemini Nano and
Gemma 4 behind one OpenAI-compatible HTTP surface. AICore is gated
behind ML Kit GenAI's Prompt API; Gemma 4 ships only as .litertlm
bundles via Google's LiteRT-LM runtime. This app stitches both into
the same /v1/chat/completions endpoint so every app on the device
(or every device on your LAN) can pick the right engine per request
without shipping its own copy of either runtime.
It's the same idea as running Ollama on a laptop, except the daemon runs in your pocket.
License¶
Apache 2.0. The Gemma model weights themselves are governed by Google's Gemma Terms of Use.