Self-Attention as Kernel Regression in JAX/Flax NNX
#ml#attention#kernels#interpretability#transformers#rkhs#jax#flax#nnx#implementation#nadaraya-watson#self-attention
The explainer argued that self-attention is a Nadaraya–Watson kernel smoother that has learned its kernel and its targets end-to-end, and that this single fact, not “the matrix is plottable”, is what makes attention heads readable. This is the implementation companion: build attention from scratch in Flax NNX, turn each prose claim into an assert, and watch the one caveat (the kernel is not symmetric, so not Mercer in the strict sense) fall out of the numbers. The dimensions are tiny so every array is legible.
Scaled dot-product attention, by hand
A single attention head is three learned projections and a softmax. In nnx.Linear the kernel maps the last axis, so the module reads the same whether x is one token or a sequence.
import jax
import jax.numpy as jnp
from flax import nnx
class Head(nnx.Module):
def __init__(self, d_model, d_head, *, rngs: nnx.Rngs):
self.wq = nnx.Linear(d_model, d_head, use_bias=False, rngs=rngs)
self.wk = nnx.Linear(d_model, d_head, use_bias=False, rngs=rngs)
self.wv = nnx.Linear(d_model, d_head, use_bias=False, rngs=rngs)
def __call__(self, x): # x: [L, d_model]
q, k, v = self.wq(x), self.wk(x), self.wv(x)
d = q.shape[-1]
scores = q @ k.T / jnp.sqrt(d) # [L, L]
alpha = jax.nn.softmax(scores, axis=-1) # rows are probability vectors
return alpha @ v, alpha
head = Head(d_model=16, d_head=16, rngs=nnx.Rngs(0))
x = jax.random.normal(jax.random.key(1), (6, 16))
y, alpha = head(x)That is the whole object. alpha is a row-stochastic matrix, each row a distribution over tokens, and y is the row-weighted average of the value vectors. Everything the explainer says follows from those two sentences.
It is Nadaraya–Watson, and you can assert it
The classical Nadaraya–Watson estimator predicts at a query by normalizing a kernel over observations and using it to weight the targets: . Write that estimator with no reference to attention, just a kernel, a normalizer, and a weighted sum of targets, and feed it the exp-dot-product kernel:
def nadaraya_watson(q, k, v, kernel):
K = kernel(q, k) # [Lq, Lk] nonnegative similarities
w = K / K.sum(axis=-1, keepdims=True) # normalize: rows sum to one
return w @ v, w
q, kk, v = head.wq(x), head.wk(x), head.wv(x)
exp_dot = lambda q, k: jnp.exp(q @ k.T / jnp.sqrt(q.shape[-1]))
y_nw, w_nw = nadaraya_watson(q, kk, v, exp_dot)
assert jnp.allclose(y_nw, y, atol=1e-5) # same output
assert jnp.allclose(w_nw, alpha, atol=1e-5) # same weightsThe two are not analogous; they are the same array up to relabeling. The dictionary is exact:
| Kernel regression | Self-attention | In the code |
|---|---|---|
| query point | query projection | head.wq(x) |
| observation | key projection | head.wk(x) |
| kernel | exp_dot | |
| target | value projection | head.wv(x) |
| normalizer | softmax denominator | K.sum(-1) |
Softmax is not a special activation that happens to live inside transformers. It is the Nadaraya–Watson normalizer applied to one specific kernel.
The kernel is not symmetric, that is the whole RKHS caveat
The explainer flags one wrinkle: queries and keys use different projections and , so the score is a bilinear form whose operator has no reason to be symmetric. A genuine (Mercer) kernel must be symmetric and positive semi-definite. This one is neither, and you can watch it fail:
wq, wk = head.wq.kernel.value, head.wk.kernel.value # [d_model, d_head]
M = wq @ wk.T # score_ij = x_i^T M x_j
print("operator symmetric? ", bool(jnp.allclose(M, M.T))) # False
S = x @ M @ x.T # raw scores q_i · k_j
sym_eigs = jnp.linalg.eigvalsh(0.5 * (S + S.T)) # symmetric part
print("score symmetric? ", bool(jnp.allclose(S, S.T))) # False
print("eig span of sym part:", float(sym_eigs.min()), float(sym_eigs.max()))
# min < 0 < max -> indefinite, so NOT positive semi-definite, so not MercerContrast with the symmetric exp-inner-product kernel on a single set of vectors, which is positive definite (it is a Hadamard exponential of a Gram matrix, a Schur product of PSD matrices):
z = jax.random.normal(jax.random.key(2), (6, 16))
G = jnp.exp(z @ z.T / jnp.sqrt(16))
print("symmetric exp-dot min eig:", float(jnp.linalg.eigvalsh(G).min())) # >= 0So the non-Mercer-ness comes entirely from , not from the exponential. Here is the subtle part the explainer leans on: softmax rescues the readout but not the kernel. Normalizing the rows makes alpha a stochastic matrix, nonnegative weights summing to one, so the output is still an honest convex combination of values (the attribution story survives). Positive-definiteness of the kernel is a different property, and it stays broken. The convex-readout companion makes the same nonnegative-is-not-positive-definite distinction from the readout side.
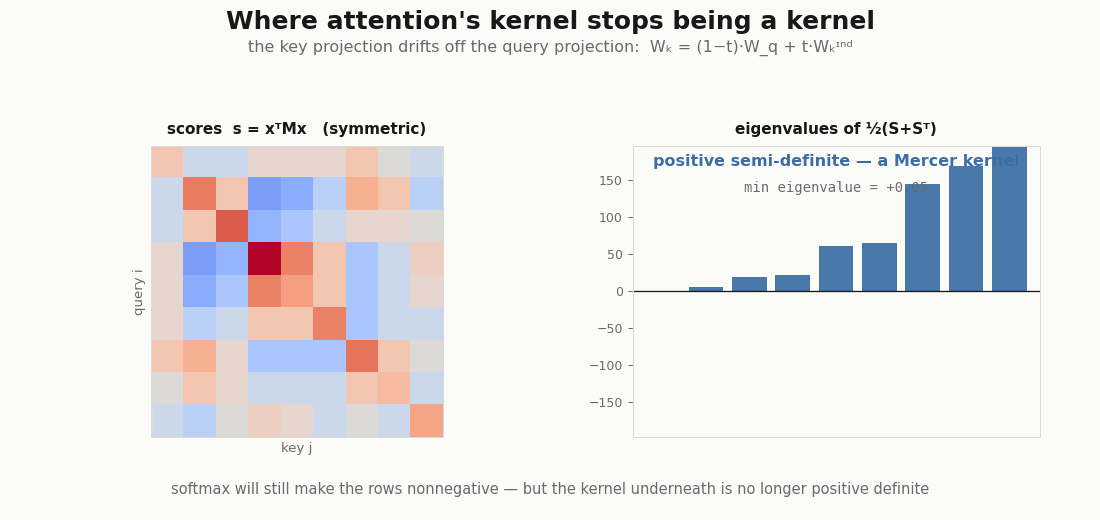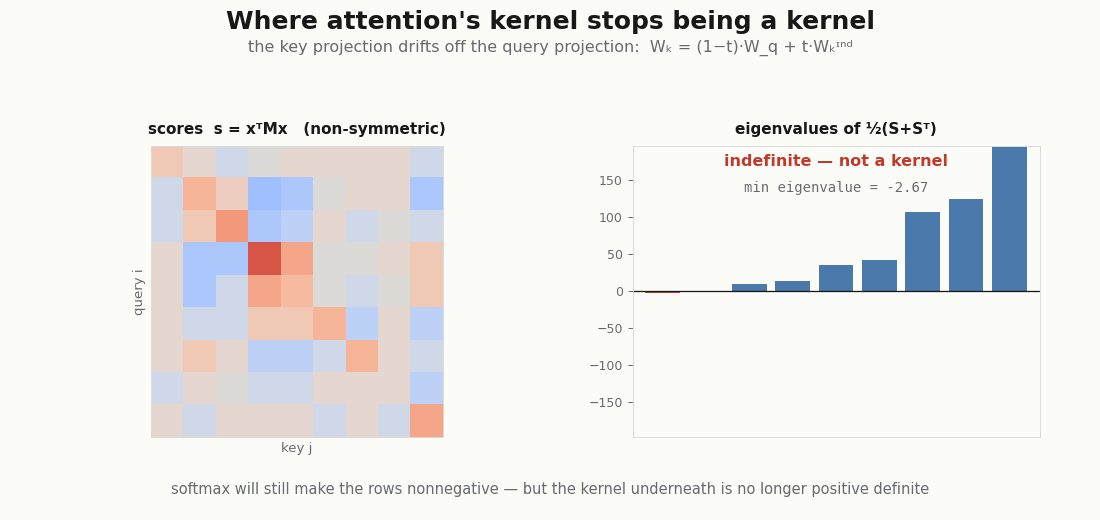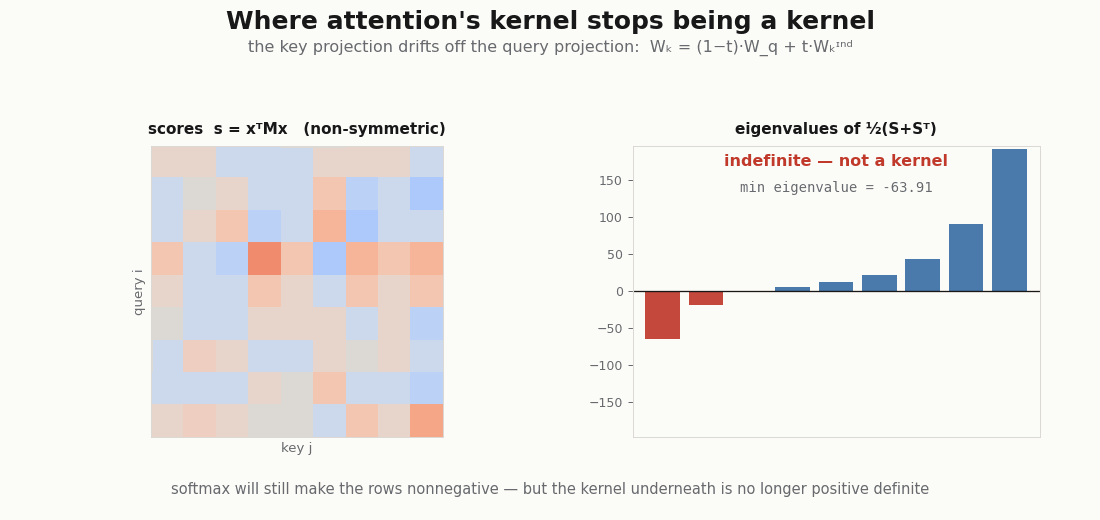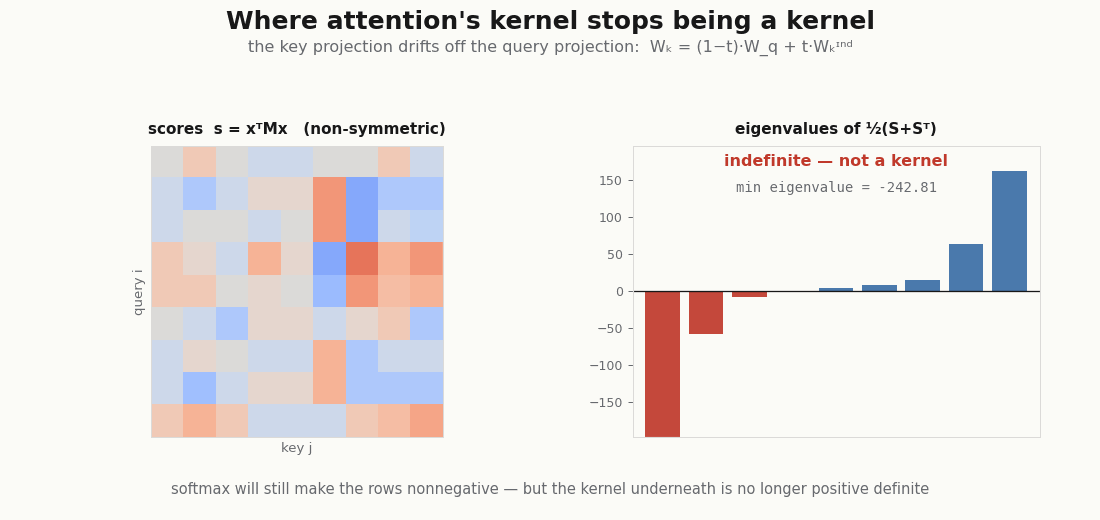
scripts/render_attention_psd_gif.py.Swapping the kernel
If attention is Nadaraya–Watson, the exp-dot-product is just one entry in the kernel slot. Drop in others through the same normalizer and ask the only question that decides whether the weights are an attribution: are they nonnegative?
def sqdist(a, b):
return jnp.sum((a[:, None, :] - b[None, :, :]) ** 2, axis=-1)
d = q.shape[-1]
kernels = {
"exp-dot (softmax)": lambda q, k: jnp.exp(q @ k.T / jnp.sqrt(d)),
"gaussian": lambda q, k: jnp.exp(-sqdist(q, k) / (2.0 * d)),
"yat": lambda q, k: (q @ k.T) ** 2 / (sqdist(q, k) + 1e-3),
"linear (signed)": lambda q, k: q @ k.T,
}
for name, kf in kernels.items():
_, w = nadaraya_watson(q, kk, v, kf)
nonneg = bool((w >= -1e-8).all())
sums_to_one = bool(jnp.allclose(w.sum(-1), 1.0, atol=1e-5))
print(f"{name:18s} nonneg={nonneg!s:5} rows_sum_to_1={sums_to_one}")
# exp-dot, gaussian, yat -> nonneg=True (valid mixtures; "30% from token j" means something)
# linear (signed) -> nonneg=False (weights can be negative, denominator can cross zero)The exp-dot-product, the Gaussian, and the Yat kernel all keep the row a probability vector, so the output stays inside the convex hull of the values and “this token contributed ” is a real statement. The linear kernel divides by a sum that can pass through zero and hands back signed “weights”, a smoother in algebra only. Nonnegativity, not positive-definiteness, is what buys the interpretation.
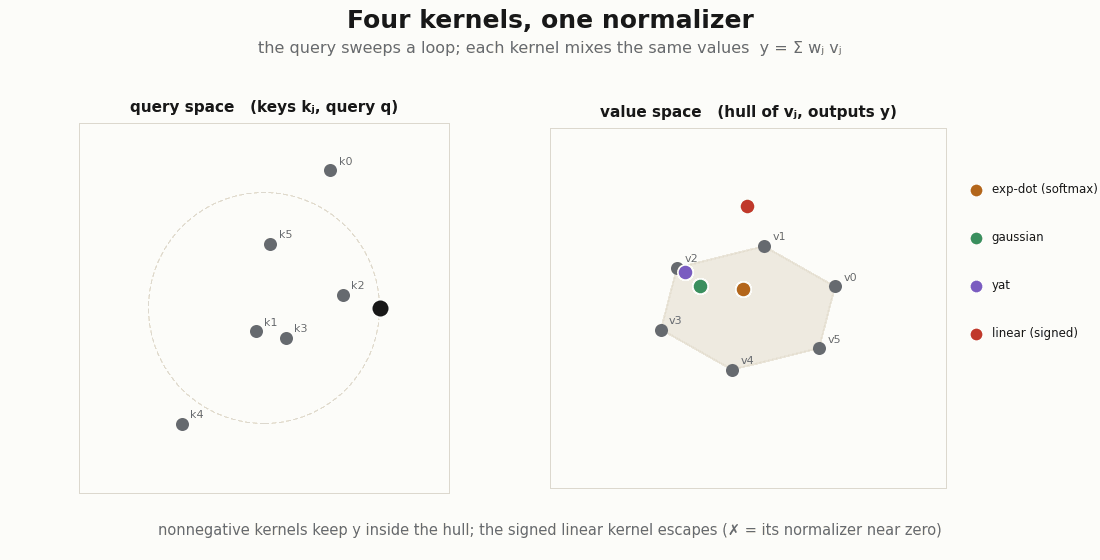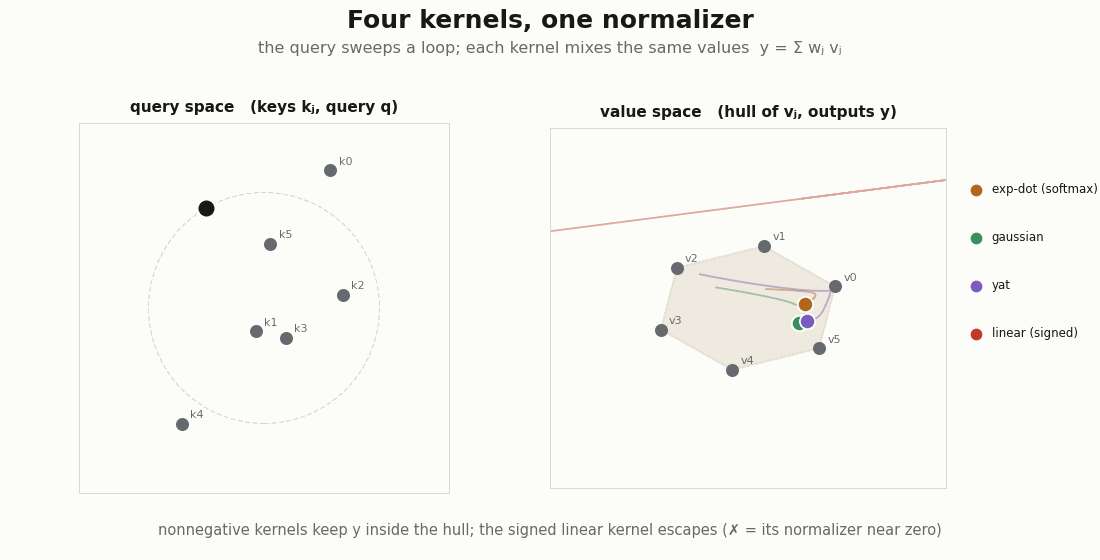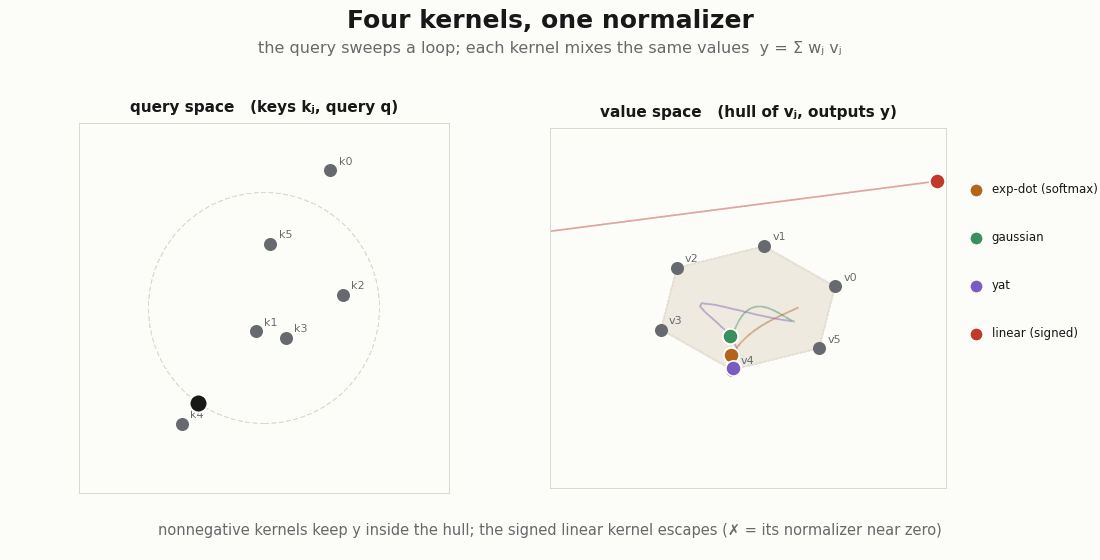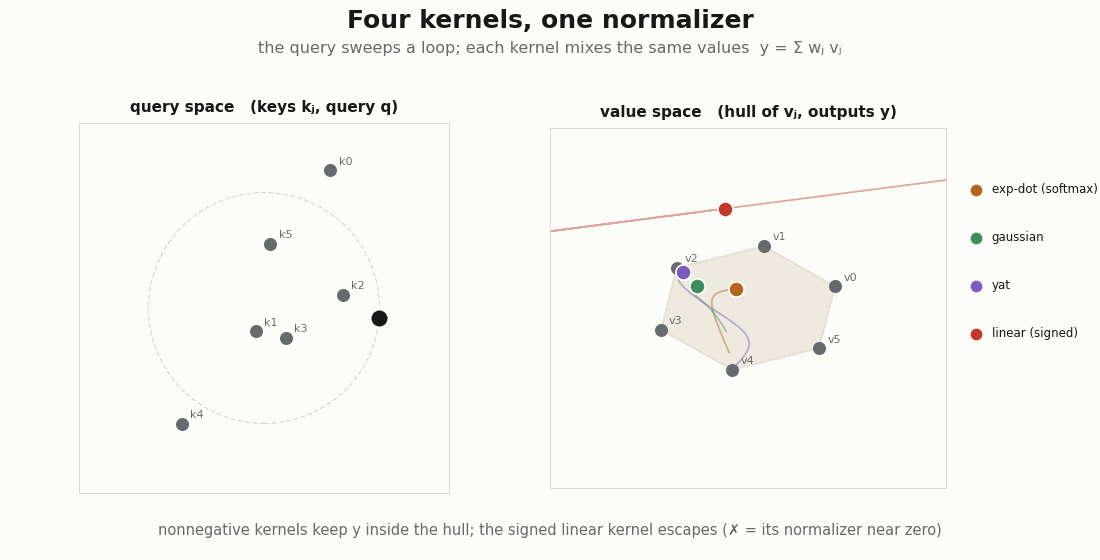
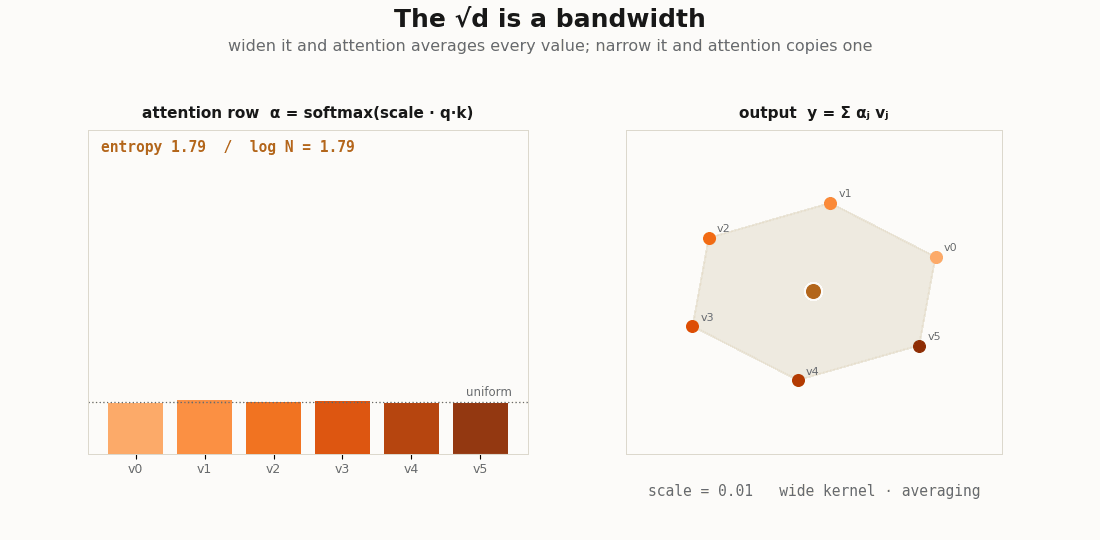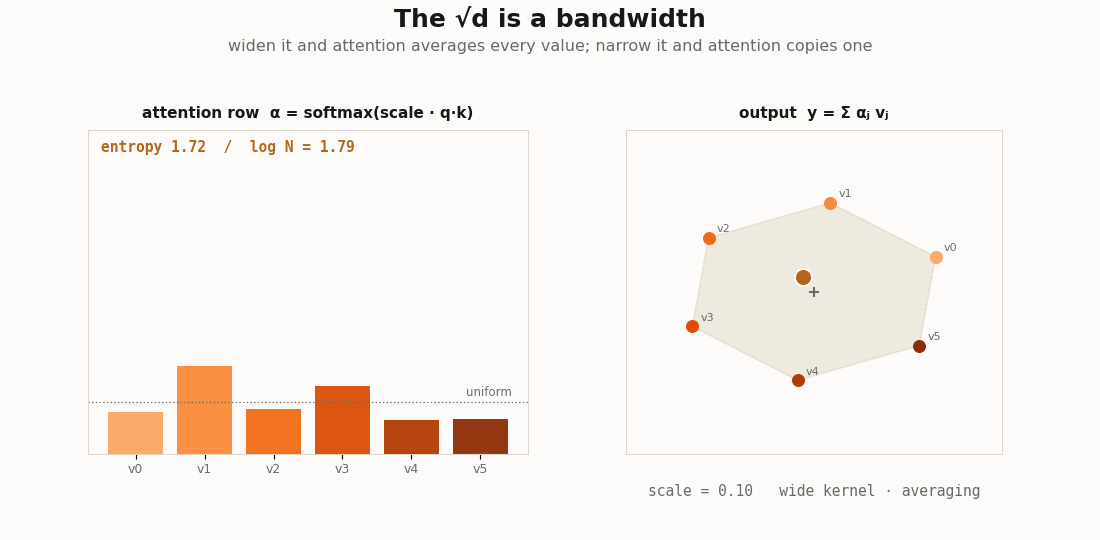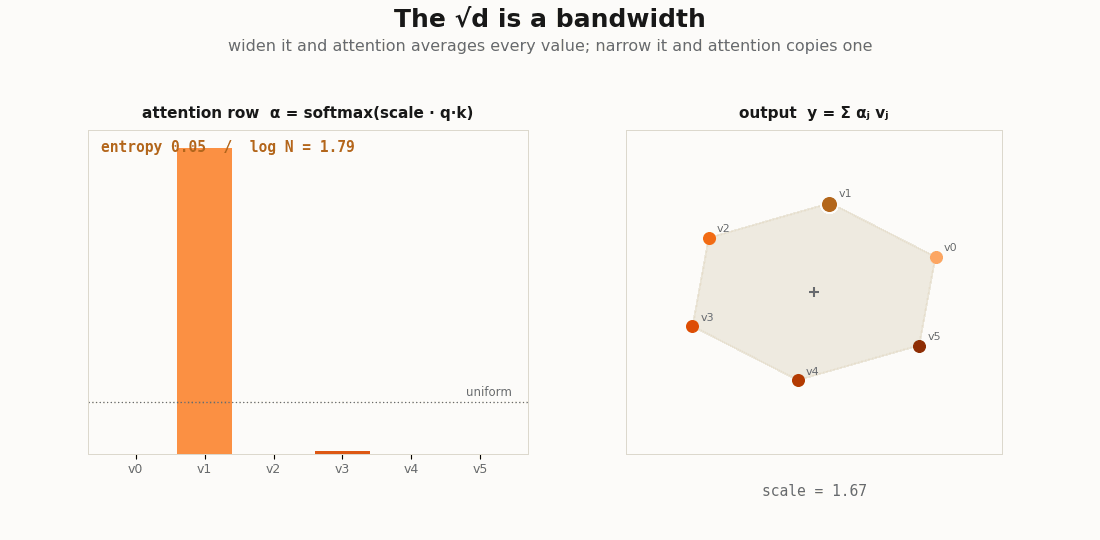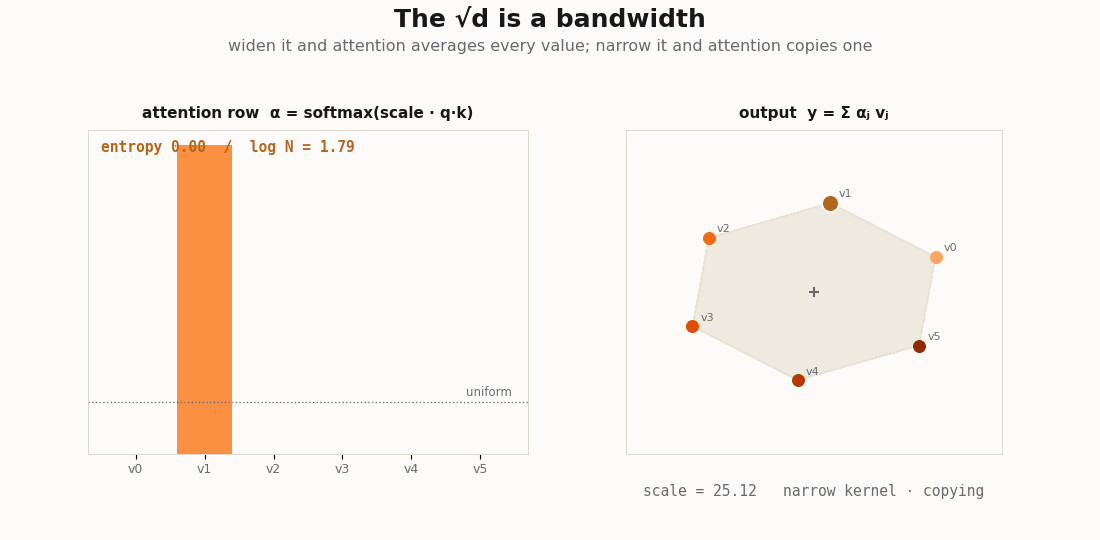
scripts/render_attention_kernels_gif.py.The √d is a bandwidth
In a kernel smoother the bandwidth sets how far the averaging reaches. In attention the same dial is the temperature on the scores. Sweep it and read the mean entropy of the rows:
def weights_at(scale):
return jax.nn.softmax((q @ kk.T) * scale, axis=-1)
def mean_entropy(w):
return float(-jnp.sum(w * jnp.log(w + 1e-12), axis=-1).mean())
for scale in [0.0, 1.0 / jnp.sqrt(d), 1.0, 6.0]:
print(f"scale={float(scale):.3f} mean row entropy={mean_entropy(weights_at(scale)):.3f}")
# scale 0 -> uniform averaging, entropy ~ log(L) (a wide kernel: every token counts equally)
# large -> entropy -> 0, a near one-hot row (a narrow kernel: nearest-neighbor copy)A wide bandwidth makes the head a blur over all tokens; a narrow one makes it a hard copy from the single most similar token. The “copy” and induction heads the interpretability literature names are kernel smoothers run at the sharp end of this dial, the temperature is not a training nuisance, it is the bandwidth of the regression.
scripts/render_attention_bandwidth_gif.py.A head that routes to a marked token
To see the kernel learn, give one head a job: in each sequence one token is flagged (a large value in its first coordinate), and every position must output that token’s vector. The head can only succeed by learning that route attention onto the flag and a that copies. One detail earns its keep here, the projections need a bias. Every query has to point at the same token regardless of its own content, and a bias-free linear map of mean-zero inputs cannot produce a content-independent pull in a fixed direction; the constant term is exactly what lets the query lean on the flag. Written batched with einsum, the module is otherwise unchanged in spirit:
import optax
class BatchHead(nnx.Module):
def __init__(self, d_model, d_head, *, rngs: nnx.Rngs):
self.wq = nnx.Linear(d_model, d_head, use_bias=True, rngs=rngs)
self.wk = nnx.Linear(d_model, d_head, use_bias=True, rngs=rngs)
self.wv = nnx.Linear(d_model, d_head, use_bias=True, rngs=rngs)
def __call__(self, x): # x: [..., L, d_model]
q, k, v = self.wq(x), self.wk(x), self.wv(x)
scores = jnp.einsum('...id,...jd->...ij', q, k) / jnp.sqrt(q.shape[-1])
a = jax.nn.softmax(scores, axis=-1)
return jnp.einsum('...ij,...jd->...id', a, v), a
def make_example(key):
k1, k2 = jax.random.split(key)
x = jax.random.normal(k1, (6, 16))
t = jax.random.randint(k2, (), 0, 6) # the marked position
x = x.at[t, 0].set(6.0) # the flag
target = jnp.broadcast_to(x[t], (6, 16)) # every row should become token t
return x, target
xs, targets = jax.vmap(make_example)(jax.random.split(jax.random.key(3), 512))
model = BatchHead(d_model=16, d_head=16, rngs=nnx.Rngs(0))
optimizer = nnx.Optimizer(model, optax.adam(1e-2), wrt=nnx.Param)
@nnx.jit
def train_step(model, optimizer, xs, targets):
def loss_fn(model):
ys, _ = model(xs)
return jnp.mean((ys - targets) ** 2)
loss, grads = nnx.value_and_grad(loss_fn)(model)
optimizer.update(model, grads)
return loss
for step in range(600):
loss = train_step(model, optimizer, xs, targets)
print("final loss:", float(loss)) # ~0.0, the target is exactly reconstructableThe head drives the loss to zero, and the learned kernel does exactly what the task demands, it concentrates all of its weight on the flagged token:
_, a = model(xs)
routed = a[:, 0, :].argmax(-1) # where position 0 sends its weight, per sequence
marker = xs[:, :, 0].argmax(-1) # the flagged token, per sequence
print("routes to the marker:", float((routed == marker).mean())) # 1.0No supervision named the marker; the head discovered that the way to minimize the loss is to put a sharp kernel on it. That discovered kernel is the explanation of what the head does, which is the explainer’s whole point, now a printed number.
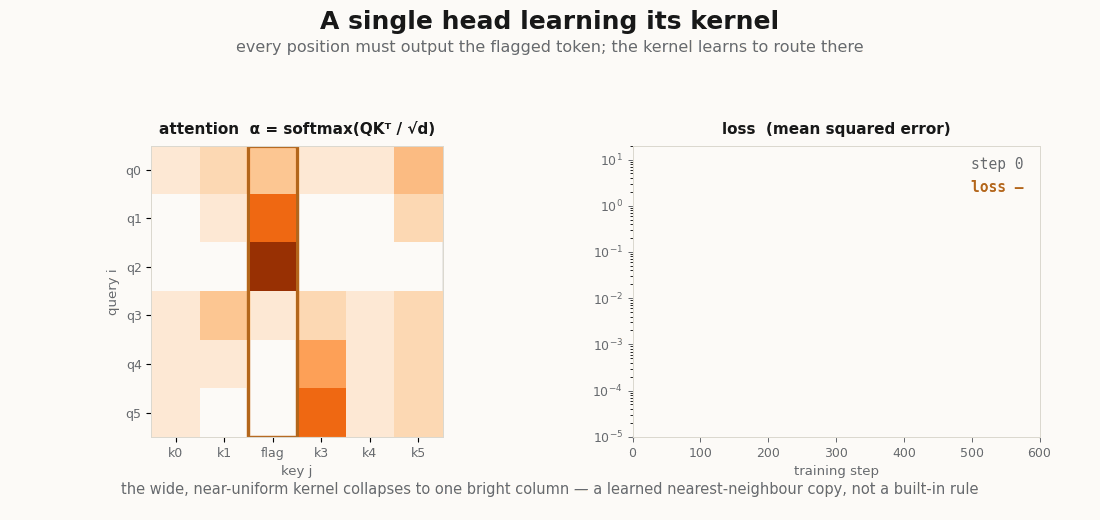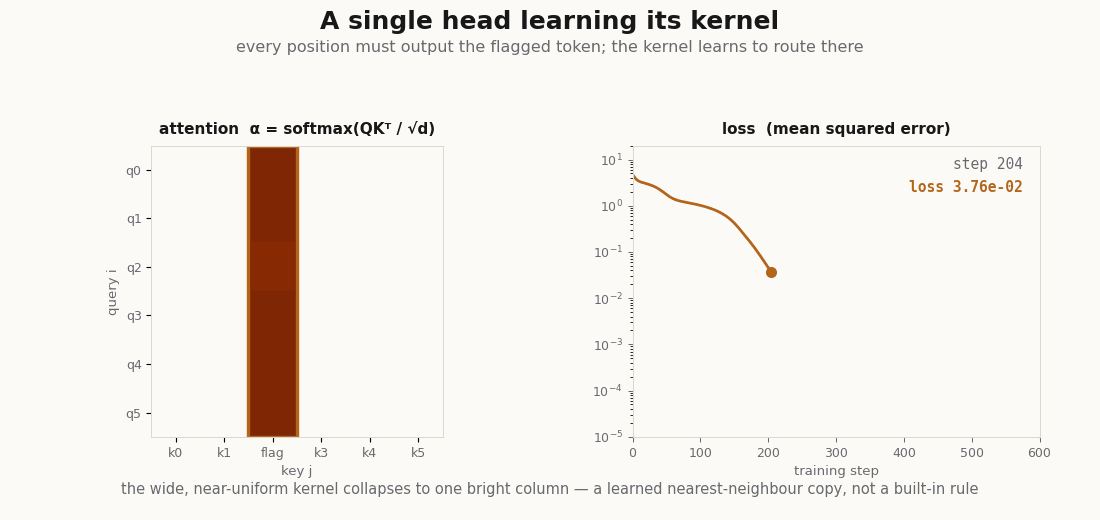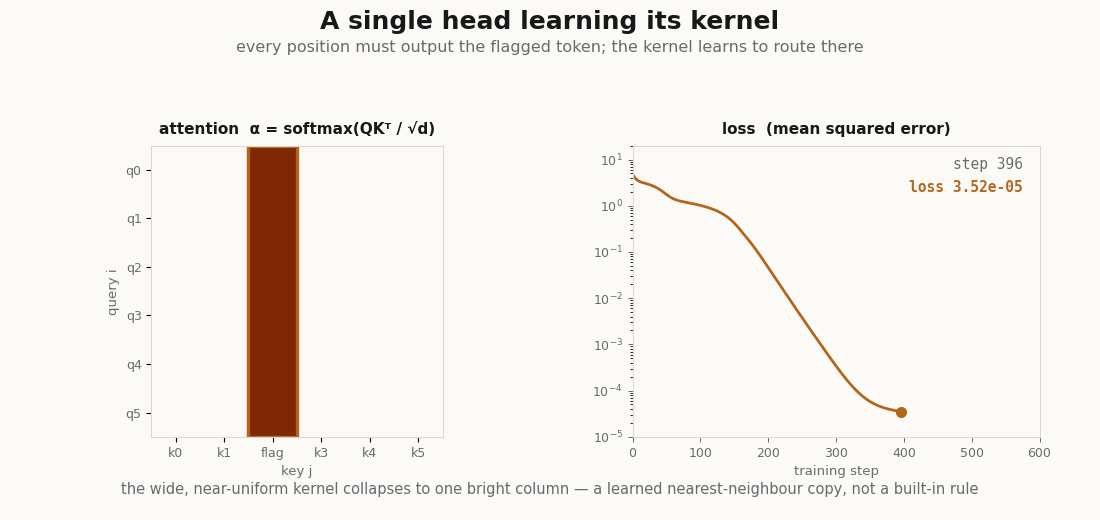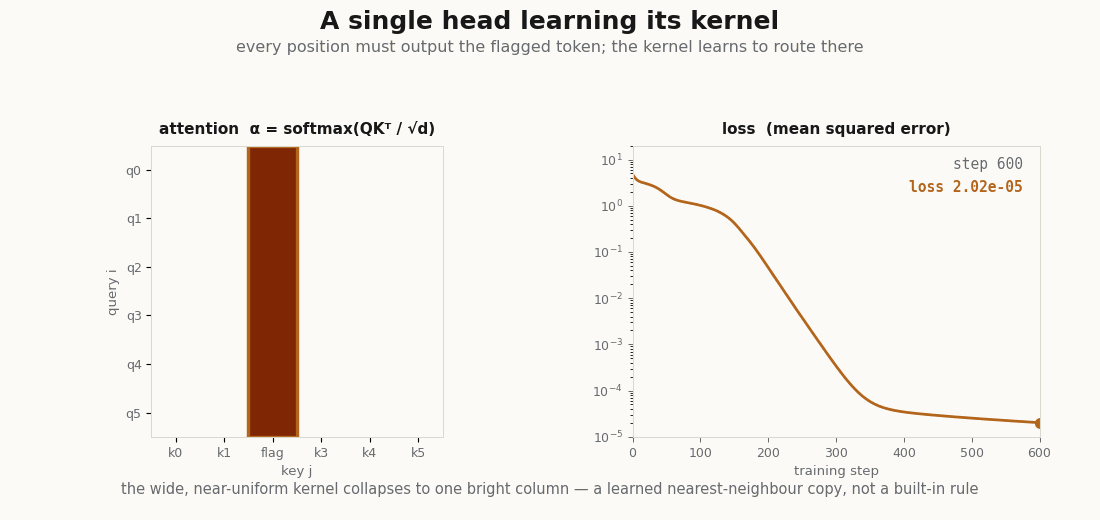
scripts/render_attention_kernel_gif.py, which runs the exact training loop above and draws the kernel each frame.What this leaves out
A real attention layer stacks many heads, carries a causal mask (a jnp.tril that sets the upper triangle to -jnp.inf before the softmax), and caches keys and values at inference. None of that touches the kernel reading: each head is its own Nadaraya–Watson smoother with its own learned kernel, and the mask just restricts which observations a query is allowed to see.
The non-positive-definiteness is also not only a curiosity. It is exactly what the linear-attention companion has to confront: to make attention cheap you replace the exp-dot-product kernel with an explicit feature map , and the honesty of that approximation (Performer; Katharopoulos et al.) is a statement about how well a positive-definite surrogate stands in for a kernel that never was one. The smoother view is what makes that question askable.
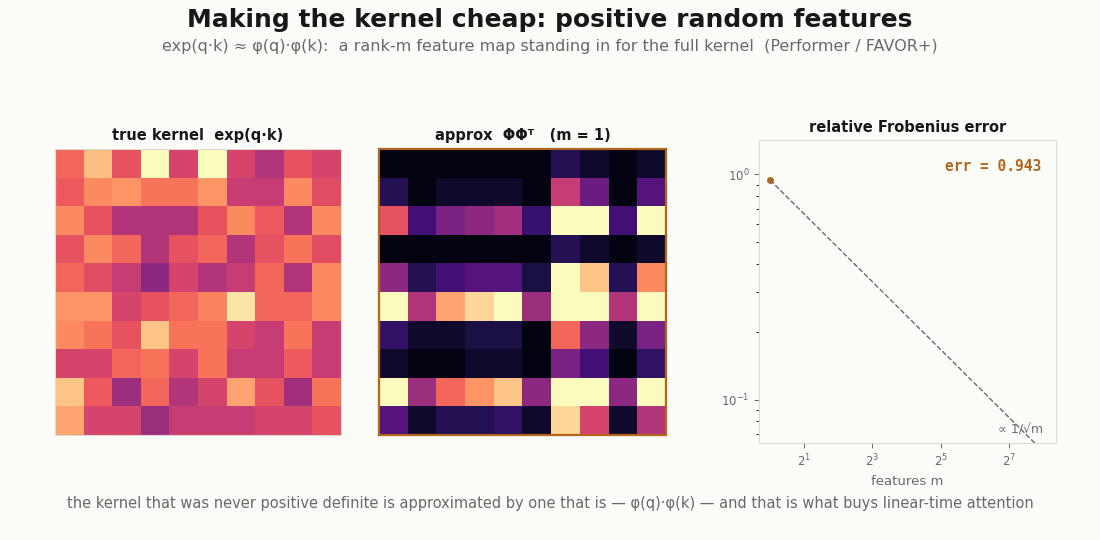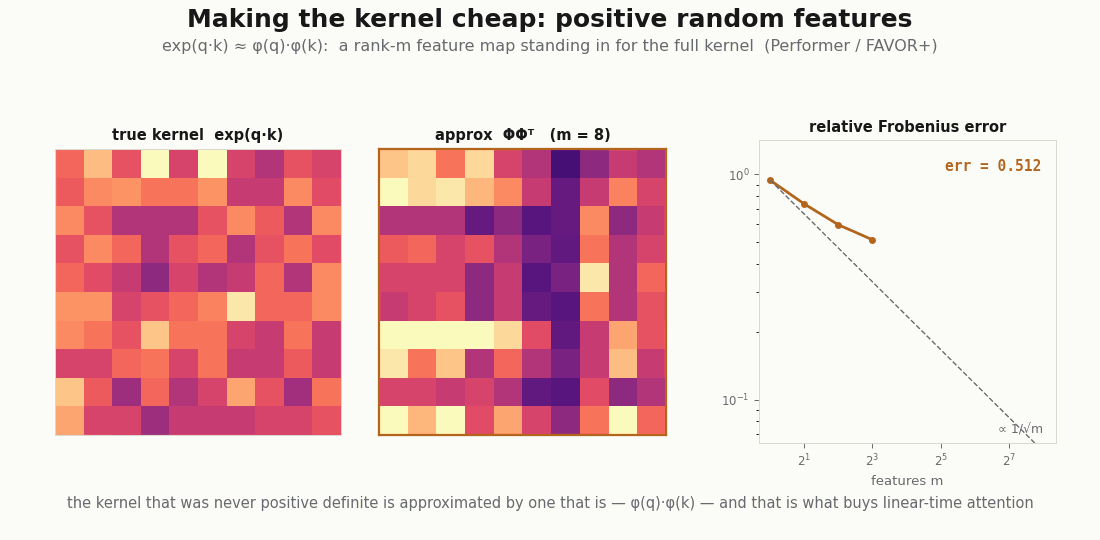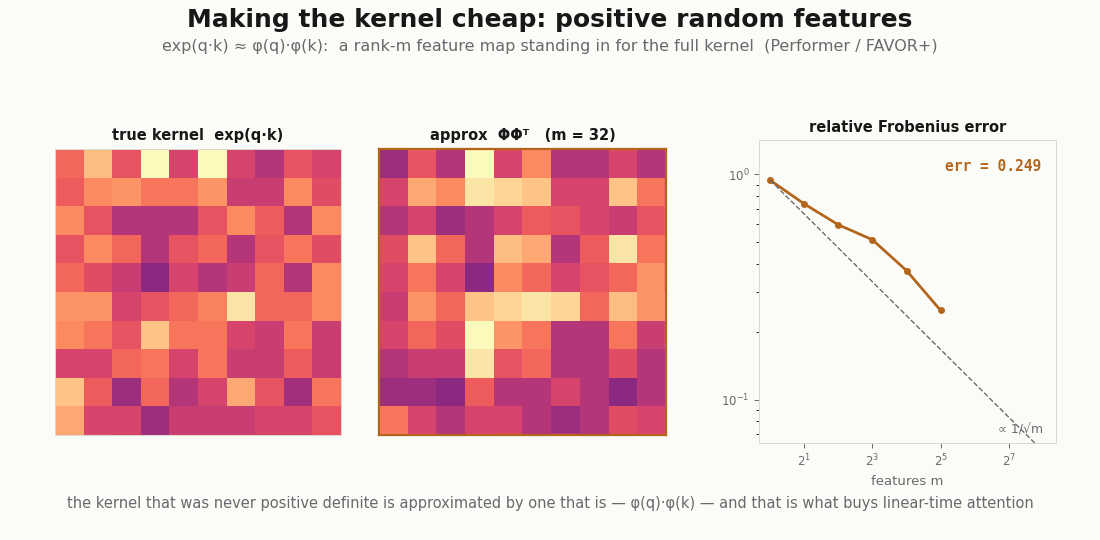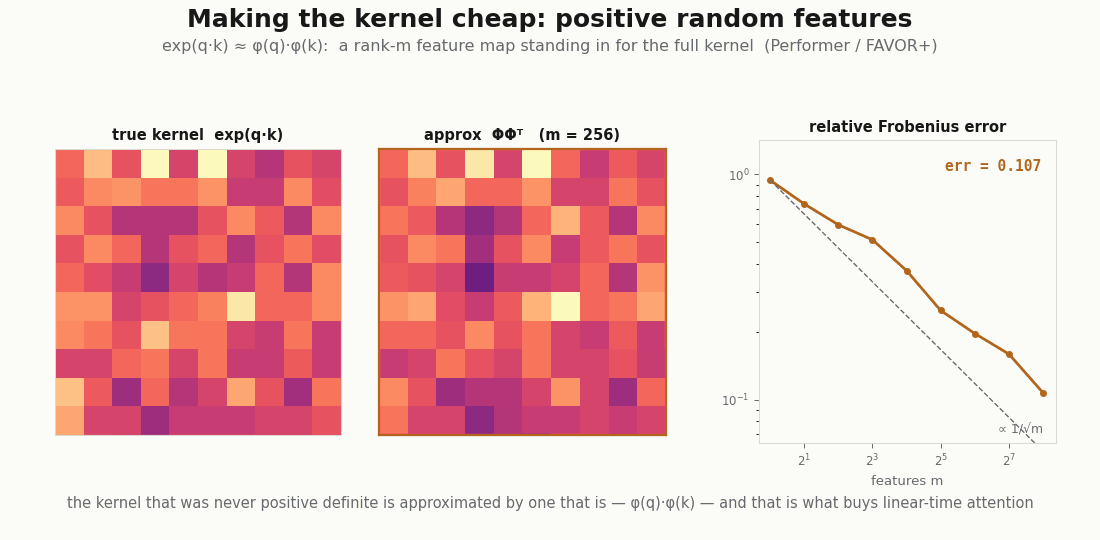
scripts/render_attention_features_gif.py.References: Flax NNX Module API; the kernel lens on attention from Tsai et al. (2019); Nadaraya–Watson regression from Nadaraya (1964) and Watson (1964); linear-attention feature maps from Katharopoulos et al. (2020) and Choromanski et al. (2021).
Cite as
Bouhsine, T. (). Self-Attention as Kernel Regression in JAX/Flax NNX. Records of the !mmortal Data Scientist. https://tahabouhsine.com/blog/attention-is-kernel-jax-flax-nnx/
BibTeX
@misc{bouhsine2026attentioniskerneljaxflaxnnx,
author = {Bouhsine, Taha},
title = {Self-Attention as Kernel Regression in JAX/Flax NNX},
year = {2026},
month = {jun},
howpublished = {\url{https://tahabouhsine.com/blog/attention-is-kernel-jax-flax-nnx/}},
note = {Blog post, Records of the !mmortal Data Scientist}
}References
- (1964). On Estimating Regression. Theory of Probability & Its Applications 9(1), 141–142.
- (1964). Smooth Regression Analysis. Sankhyā: The Indian Journal of Statistics, Series A 26(4), 359–372.
- (2019). Transformer Dissection: An Unified Understanding for Transformer's Attention via the Lens of Kernel. EMNLP-IJCNLP 2019.
- (2020). Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. ICML 2020.arXiv:2006.16236
- (2021). Rethinking Attention with Performers. ICLR 2021.arXiv:2009.14794
- (2026). A Universal Reproducing Kernel Hilbert Space from Polynomial Alignment and IMQ Distance. arXiv:2605.03262