Organizing Randomness: Contrastive Learning in JAX
#ml#contrastive#jax#optax#embeddings#contrastive-learning#infonce#supcon#siglip#triplet-loss#implementation#representation-learning#self-supervised-learning
Part 4 of 8Geometry of Representations
- 1Activations Are Bad for Geometry
- 2Opposite Is Not Different: The Cosine-Similarity Bug in CLIP and Contrastive Learning
- 3Not All Infinities Are Equal: The Cross-Entropy Asymmetry Behind Hallucination
- 4Untangling the Moons: A Visual History of Contrastive Learningthis post's explainer
- 5What Makes a Good Latent Space? The Welch Bound and the Simplex
- 6Latent on the Spectrum: Why Cats Sit Closer to Dogs Than to Cars
- 7The Three States of Information
- 8Distillation Is a Geometry, Not an Answer Key
The runnable companion to Untangling the Moons. There I raced the losses; here I build them.
Prefer a notebook? Run the whole thing on Kaggle: the same code, block by block, with the math written out and every figure reproduced from a real run.
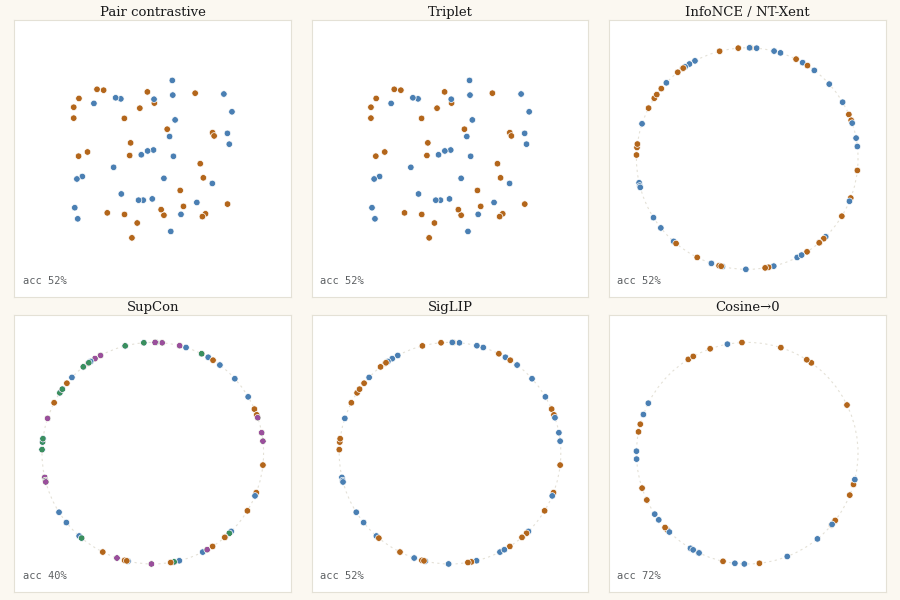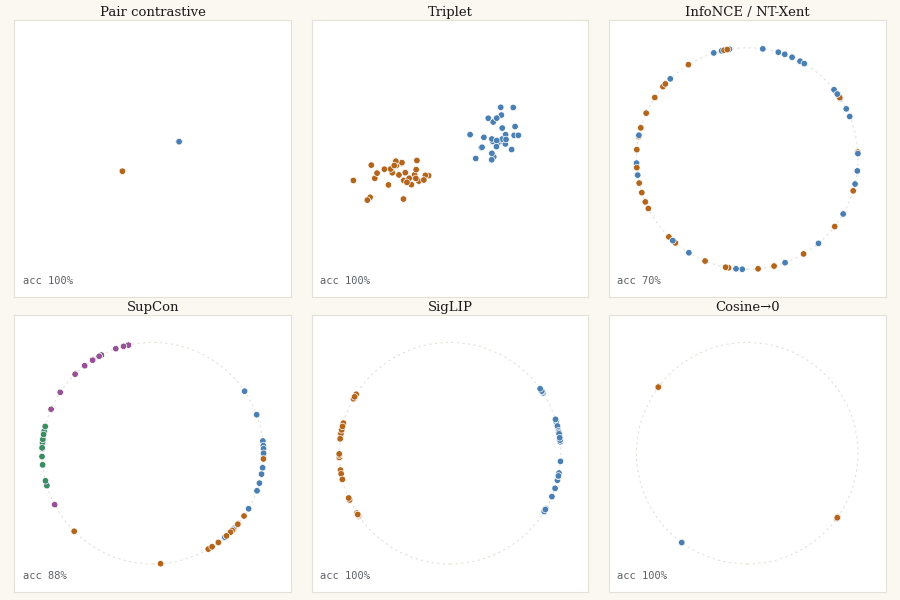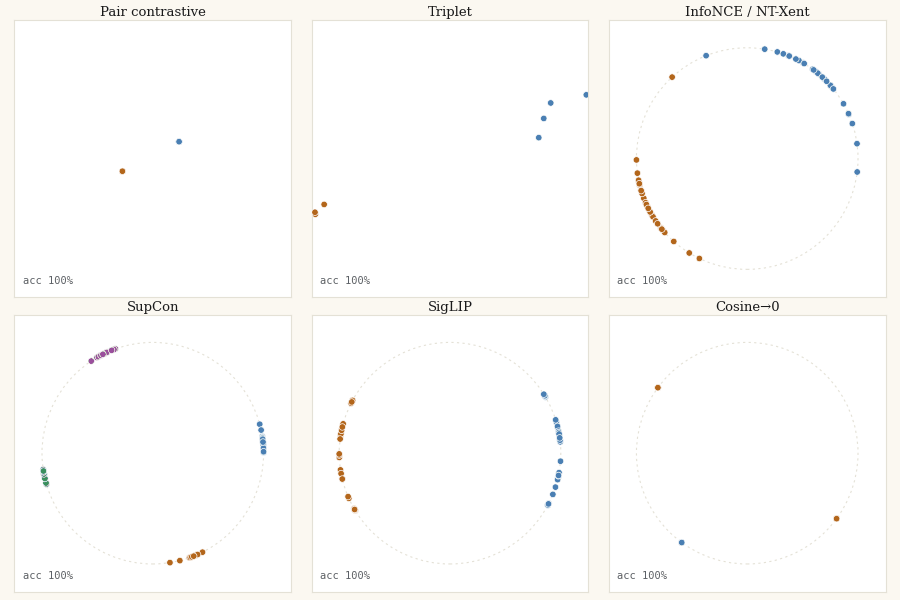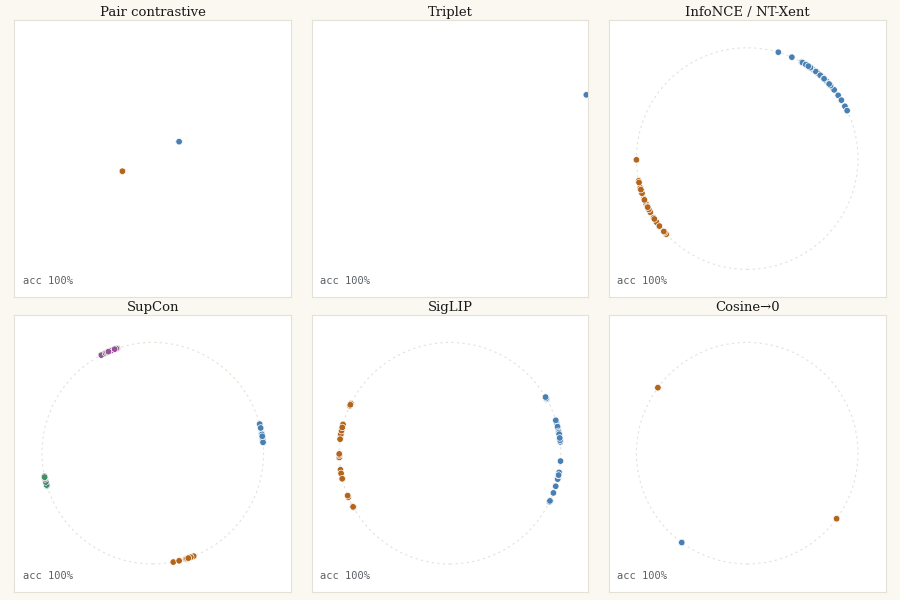
In Untangling the Moons I argued that the whole contrastive-learning lineage disagrees about one geometric question, how far apart should different-class points be?, and let you watch eight losses answer it in an interactive playground. This post is the other half: the actual JAX code that moves the points, and the same chaos-to-order trajectory rendered as a real GIF you can regenerate yourself.
The setup is the same trick that made the visualisations legible. Skip the encoder entirely. Take 60 points in 2D (40 for the orthogonality loss, for a reason its section owns up to), assign them random labels, and treat the positions themselves as the embeddings. Then run gradient descent on a contrastive loss and watch the points organize. Random labels on random positions means there is no spatial signal at the start, the loss has to impose every bit of geometry itself. That is the cleanest possible test of what a loss actually wants.
Every loss below is about fifteen lines of jax.numpy. The complete, runnable
generator, data, losses, training loop, and the matplotlib renderer that made
these GIFs, lives in
scripts/jax-contrastive/
in the repo.
The shared scaffolding
Everything that isn’t the loss is identical across all six, and it begins with the data: uniform points, balanced labels, then a shuffle so position tells you nothing about class.
import numpy as np
def make_random(n=60, k=2, seed=7):
"""Uniform points in [-1.5, 1.5]^2 with balanced, shuffled labels.
No spatial signal: labels are assigned i % k then shuffled, so the loss
must impose all of the geometry itself.
"""
rng = np.random.default_rng(seed)
pts = rng.uniform(-1.5, 1.5, size=(n, 2)).astype(np.float32)
labels = np.array([i % k for i in range(n)], dtype=np.int32)
rng.shuffle(labels)
return pts, labelsHalf the losses live on the unit circle, they compare directions, not positions, so cosine similarity is the natural metric. That means one helper, applied after every step:
import jax.numpy as jnp
def l2normalize(z):
return z / (jnp.linalg.norm(z, axis=1, keepdims=True) + 1e-9)The training loop is the payoff of writing each loss as a single
differentiable scalar: the optimizer, the gradient, and the JIT never change.
Swap the loss_fn and you have a different algorithm.
import jax
import optax
def make_step(loss_fn, lr, on_sphere, masks):
opt = optax.sgd(lr)
@jax.jit
def step(z, opt_state, key, param):
loss, grads = jax.value_and_grad(loss_fn)(z, None, key, param, m=masks)
updates, opt_state = opt.update(grads, opt_state)
z = optax.apply_updates(z, updates)
if on_sphere:
z = l2normalize(z) # re-project onto the unit circle
return z, opt_state, loss
return step, optTwo details worth flagging. The pairwise label masks (same, eye, triu)
depend only on the labels, never on the positions, so they are built once on
the host and closed over, that keeps the loss bodies loop-free and lets
jax.jit compile a single fused kernel:
def make_masks(labels):
same = labels[:, None] == labels[None, :]
eye = np.eye(len(labels), dtype=bool)
triu = np.triu(np.ones_like(same), k=1) # each unordered pair once
return {"same": jnp.asarray(same), "eye": jnp.asarray(eye),
"triu": jnp.asarray(triu)}And the key is threaded through every step with jax.random.split, only the
two samplers (triplet and InfoNCE) actually use it, but passing it uniformly
keeps the step signature identical for all losses. To measure progress we use
the same nearest-centroid accuracy as the visualisations: assign each point to
its closest class centroid, report the fraction that lands right. It is a cheap
linear-separability proxy, computed in NumPy on a host snapshot every few steps
along with a frame for the GIF.
Now the six losses. Each is a pure function of (z, labels, key, param)
returning one scalar, the quantity whose gradient organizes the points.
1. Pair contrastive, Hadsell, Chopra & LeCun, 2006
The original. Pull same-class pairs together quadratically; push different-class pairs apart until they hit a margin, then go silent.
def loss_pair(z, labels, key, margin, *, m):
n = z.shape[0]
diff = z[:, None, :] - z[None, :, :]
d2 = jnp.sum(diff ** 2, axis=-1)
d = jnp.sqrt(d2 + 1e-9)
upper = m["triu"] > 0
pos = jnp.where(m["same"] & upper, d2, 0.0)
neg_active = (~m["same"]) & upper & (d < margin)
neg = jnp.where(neg_active, (margin - d) ** 2, 0.0)
return (jnp.sum(pos) + jnp.sum(neg)) / n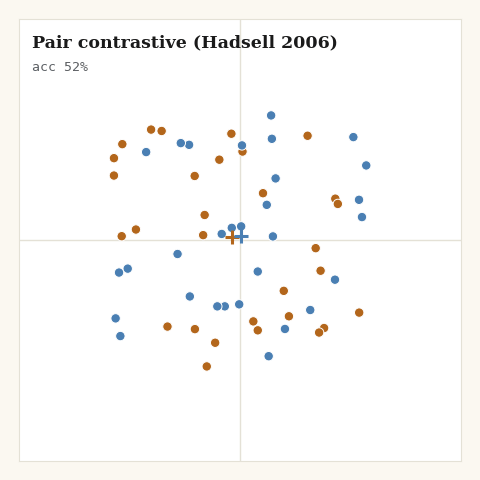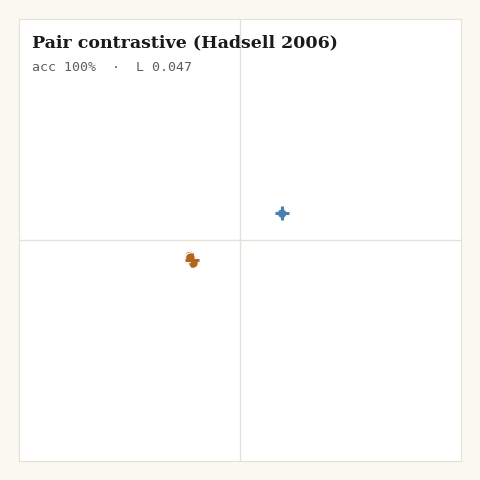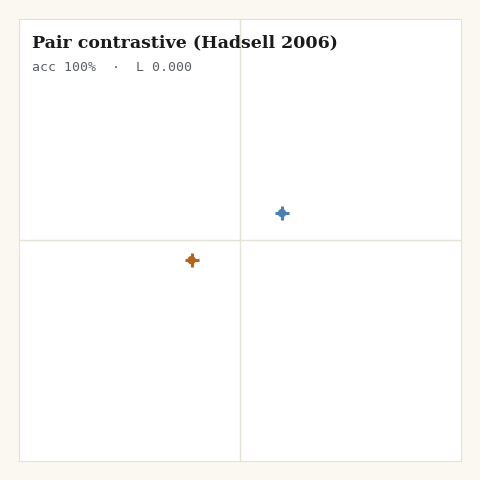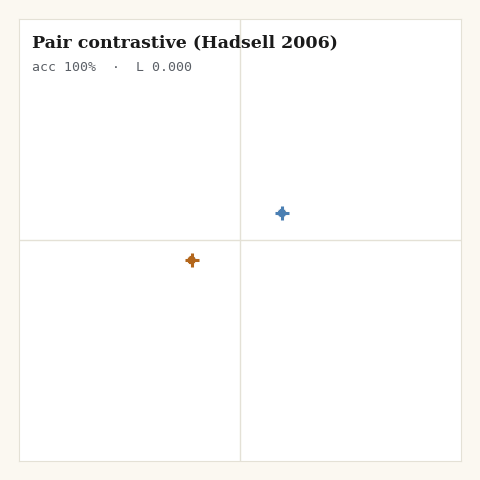
This is Euclidean, no sphere. The whole thing is one masked sum over the
pairwise distance matrix. Note the / n normalization: it matches the update
scale the interactive visualisations used, and dividing by the point count
rather than the pair count keeps the gradient strong enough to actually move 60
points in a couple hundred steps.
2. Triplet, FaceNet, 2015
What if the comparison were relative instead of global? For each anchor, sample one positive and one negative; require the negative to sit at least a margin farther than the positive. Only violating triplets contribute.
def loss_triplet(z, labels, key, margin, *, m):
kp, kn = jax.random.split(key)
pos_mask = m["same"] & (~m["eye"])
neg_mask = ~m["same"]
pidx = jax.random.categorical(kp, jnp.where(pos_mask, 0.0, -1e9), axis=1)
nidx = jax.random.categorical(kn, jnp.where(neg_mask, 0.0, -1e9), axis=1)
d_ap = jnp.sum((z - z[pidx]) ** 2, axis=1)
d_an = jnp.sum((z - z[nidx]) ** 2, axis=1)
hinge = jnp.clip(d_ap - d_an + margin, a_min=0.0)
violators = jnp.sum(hinge > 0)
return jnp.sum(hinge) / jnp.maximum(violators, 1.0)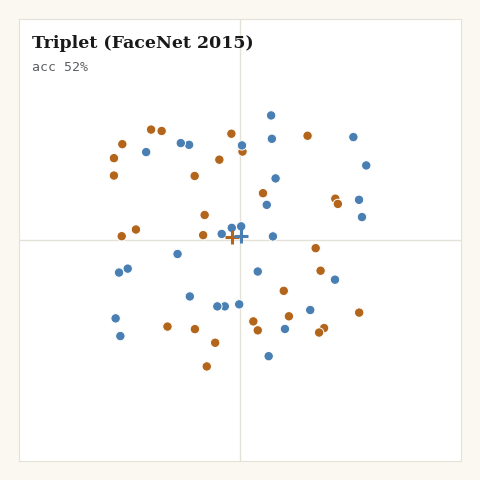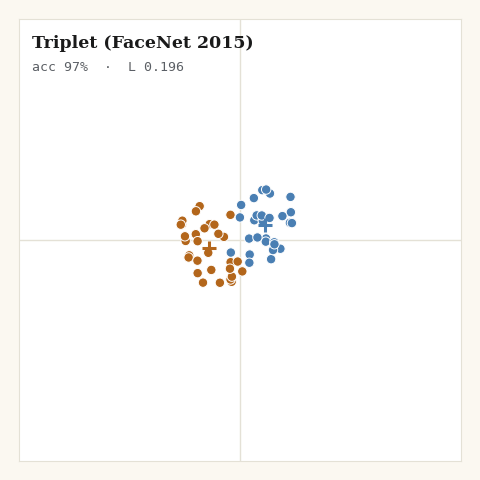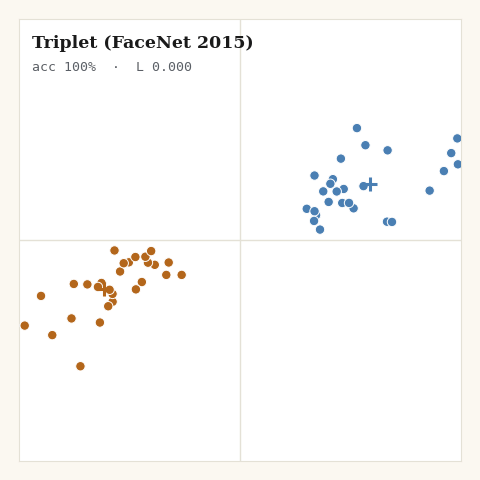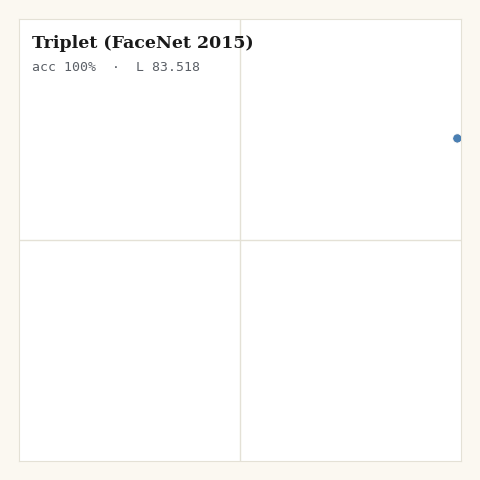
The sampling is the interesting part of the JAX. There are no Python loops:
jax.random.categorical over a masked logit row picks one positive and one
negative per anchor in a single vectorized call, fully inside jit. Setting
disallowed entries to -1e9 makes them unreachable. This is the idiom for
“sample from a per-row set” in JAX, no gather loops, no host round-trips.
3. InfoNCE / NT-Xent, van den Oord 2018, SimCLR 2020
What do you use once the hard margin keeps going silent? A softmax over cosine similarities. Every other point is a negative; the gradient never fully vanishes.
def loss_infonce(z, labels, key, tau, *, m):
sim = (z @ z.T) / tau
logits = jnp.where(m["eye"], -1e9, sim) # mask self
log_z = jax.nn.logsumexp(logits, axis=1) # over k != i
pos_mask = m["same"] & (~m["eye"])
pidx = jax.random.categorical(key, jnp.where(pos_mask, 0.0, -1e9), axis=1)
pos_sim = jnp.take_along_axis(sim, pidx[:, None], axis=1)[:, 0]
return jnp.mean(log_z - pos_sim)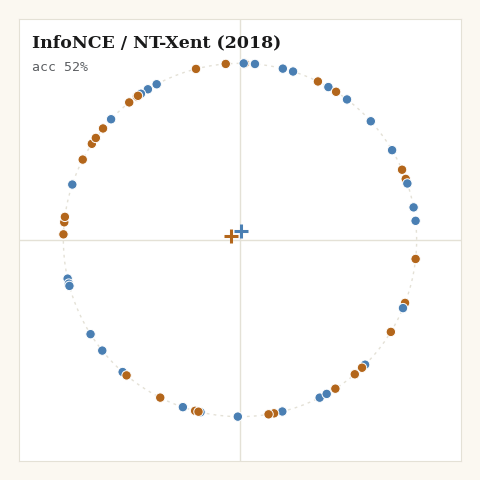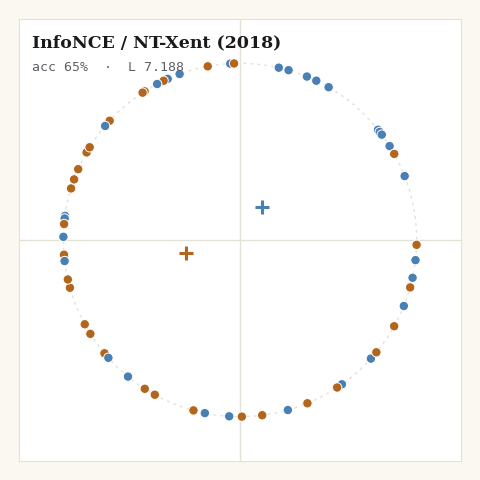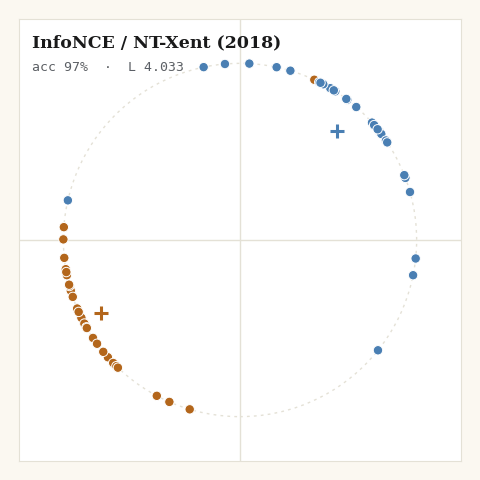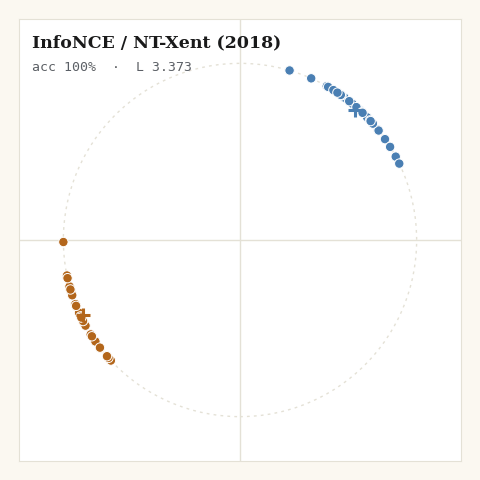
Because z is normalized, z @ z.T is the cosine matrix directly. The whole
loss is jax.nn.logsumexp doing the numerically stable denominator and one
sampled positive in the numerator. That softmax-over-similarities is exactly
the Nadaraya–Watson kernel operator I unpacked in
Attention is Explainable Because it is a Kernel,
InfoNCE is that operator pointed at a different objective.
4. SupCon, Khosla et al., 2020
When you have labels, every same-class point is a positive. Average the InfoNCE term over all of them, no sampling at all.
def loss_supcon(z, labels, key, tau, *, m):
sim = (z @ z.T) / tau
logits = jnp.where(m["eye"], -1e9, sim)
log_p = logits - jax.nn.logsumexp(logits, axis=1, keepdims=True)
pos = (m["same"] & (~m["eye"])).astype(z.dtype)
p_count = jnp.sum(pos, axis=1)
per_anchor = -jnp.sum(pos * log_p, axis=1) / jnp.maximum(p_count, 1.0)
return jnp.mean(per_anchor)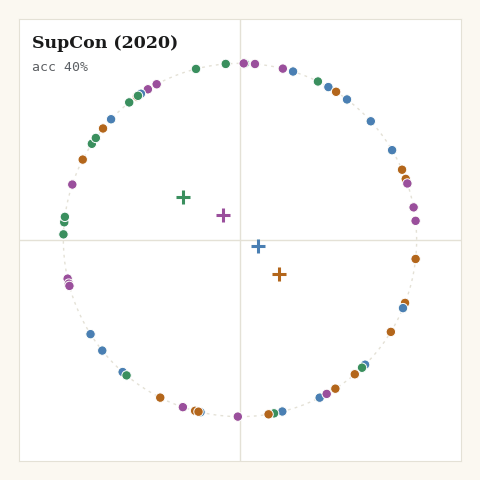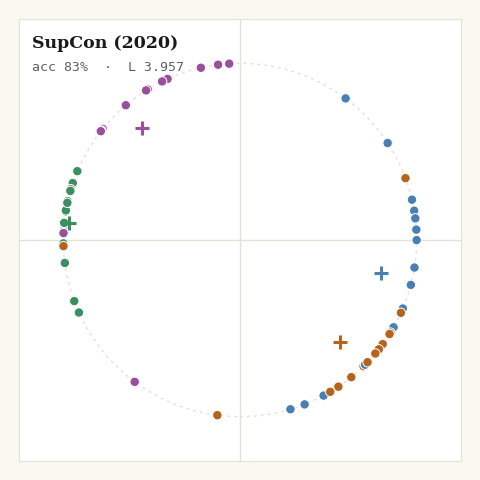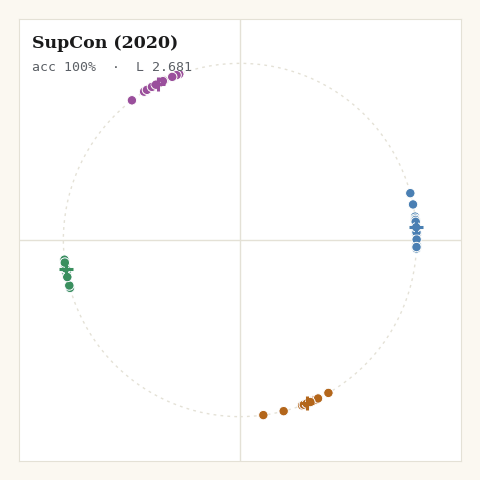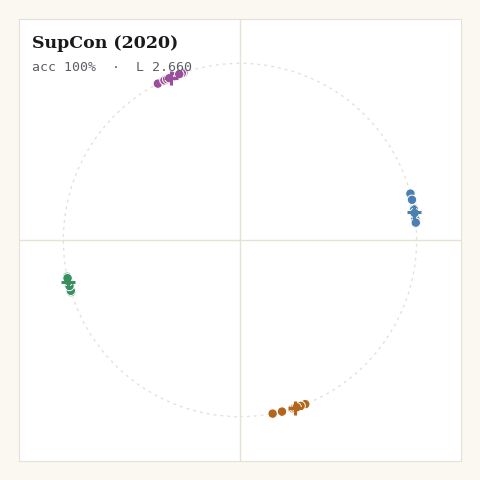
The shape from the visualisations is visible immediately: SupCon is the tightest of all the losses. Averaging over many positives is, in effect, pulling each point toward its class centroid every step. Great for downstream classification; brutal to any within-class variation you might have cared about.
5. SigLIP, Zhai et al., 2023
What if the loss let you say where the pushing should stop? SigLIP drops the softmax entirely, scores each pair independently with a sigmoid, and, crucially, puts a bias on it so you choose where different-class pairs stop being pushed apart.
def loss_siglip(z, labels, key, target, *, m):
n = z.shape[0]
t, b = 10.0, -10.0 * target
sim = z @ z.T # cosine; z on the sphere
sign = jnp.where(m["same"], 1.0, -1.0) # y_ij = +1 same / -1 diff
per_pair = jax.nn.softplus(-sign * (t * sim + b))
return jnp.sum(jnp.where(m["triu"] > 0, per_pair, 0.0)) / n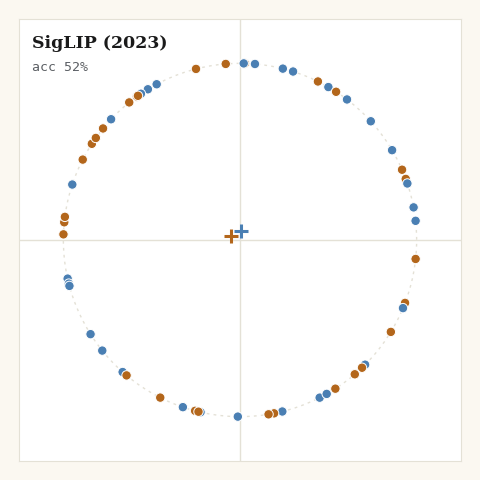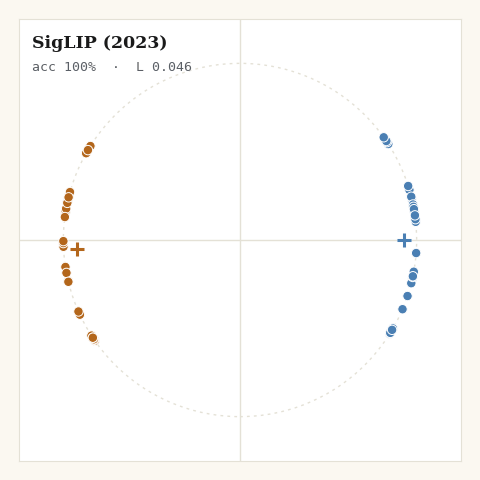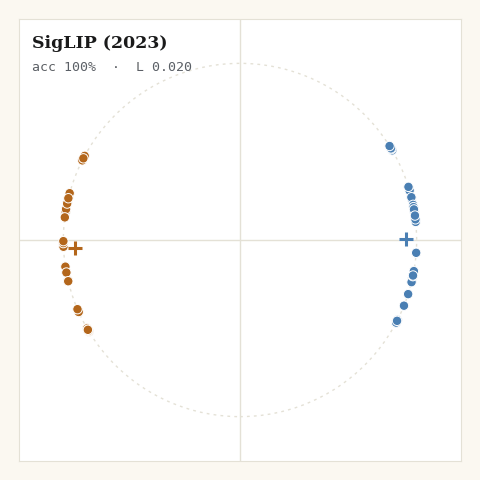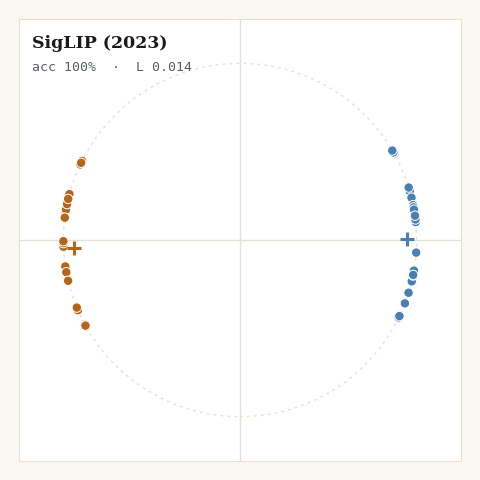
jax.nn.softplus(x) is the stable log(1 + e^x), and target sets the bias
b = -t·target, the cosine at which the loss for a negative pair goes flat.
Set it near zero and negatives equilibrate at orthogonality, not at the
diametric opposition every softmax loss implicitly chases. That is the geometric
fix I argued for in
Opposite Is Not Different.
6. Cosine→0, the orthogonality objective
The simplest objective consistent with that argument. Pull same-class pairs to cosine 1; push different-class pairs to cosine 0, orthogonality, not opposition.
def loss_orthog(z, labels, key, _unused, *, m):
n = z.shape[0]
c = z @ z.T
per_pair = jnp.where(m["same"], 1.0 - c, c ** 2)
return jnp.sum(jnp.where(m["triu"] > 0, per_pair, 0.0)) / n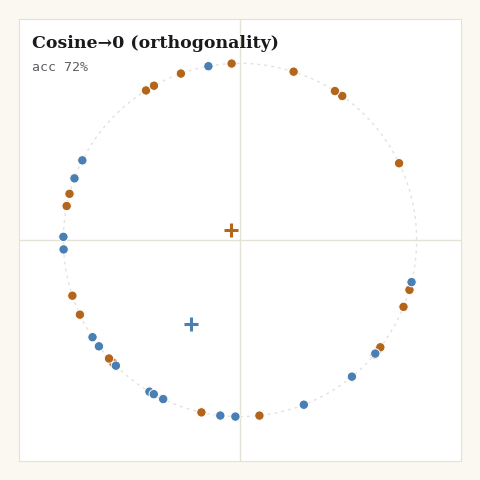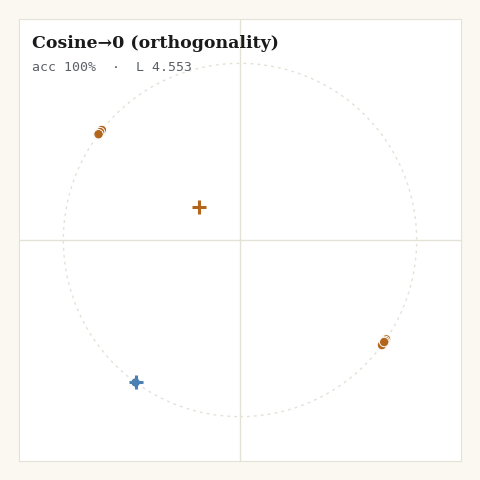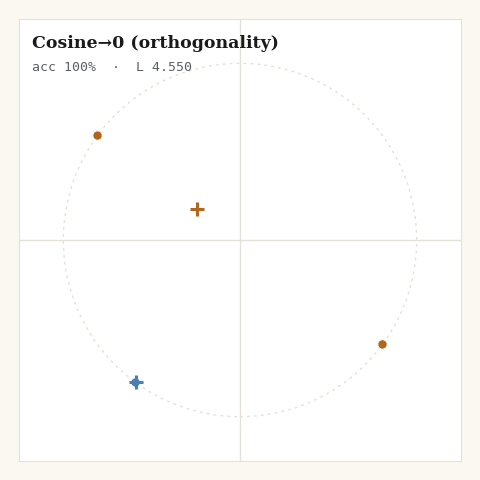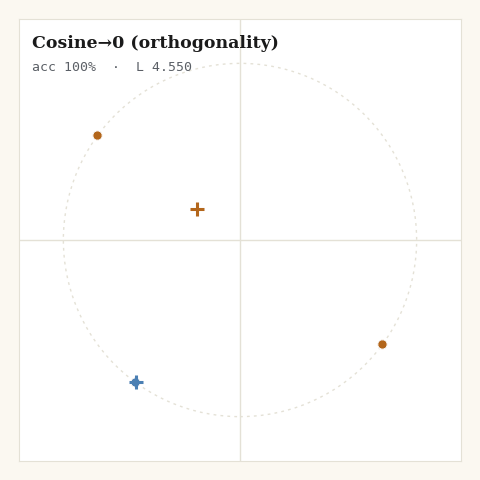
Three lines of math, and the cleanest geometry of the six: two classes land on perpendicular directions and stop, because the loss is genuinely minimized there rather than fighting the spherical geometry forever. The target is a dimension-independent approximation to the simplex optimum , nearly exact when classes are many, deliberately conservative when they are few. The companion post works through why that is the right trade, and why it only holds when the class count doesn’t exceed the dimension.
One caveat the code made me confront. From a perfectly balanced random start, this loss can stall at a symmetric configuration, each class smeared uniformly around the circle, where same-class attraction and different-class repulsion cancel. The softmax losses break that symmetry through their sampled positive or their normalization; bare orthogonality has nothing to break it with. The fix in the generator is mundane, 40 points instead of 60 and a seed that isn’t perfectly symmetric, but it is a real lesson: an objective can be correct at its minimum and still need help escaping a saddle.
The two we skipped
Two of the eight losses from the explainer never got a code block above, and
that is deliberate: neither would teach you a new line of JAX.
CLIP is symmetrized InfoNCE, run loss_infonce in both directions
(anchor→positive and positive→anchor) and average; the geometry is identical.
Alignment + Uniformity (Wang & Isola, 2020) splits InfoNCE into an explicit
pull-positives-together term and a spread-everyone-out term; both are a few more
lines in the same style. If you want to watch them move, both run live in
Untangling the Moons.
The race
The six panels side by side, each loss running on its own random cloud with its accuracy readout ticking up, which is where the disagreements become obvious.
The pattern is the one from the interactive version, now in committed, reproducible pixels: the margin family freezes once satisfied, the softmax family never stops, and only SigLIP and cosine→0 halt where the geometry actually wants them to.
Run it yourself
Everything here is deterministic given the seed. The generator is six small
files, data.py, losses.py, train.py, render.py, generate.py, in
scripts/jax-contrastive/:
pip install -r requirements.txt # jax, optax, matplotlib, imageio
python generate.py --loss all --gridEvery GIF on this page lands in public/jax-contrastive/. Change --loss,
--dataset (random, random-4, moons), --seed, or --steps and watch a
different trajectory. The optimization is reproducible to the seed; the rendered
pixels may shift slightly across matplotlib versions, so the guarantee is on the
trajectory, not the bytes.
If you want the why behind these six geometries, twenty years of why different-class points kept getting pushed too far apart, that is Untangling the Moons. This was the how.
Cite as
Bouhsine, T. (). Organizing Randomness: Contrastive Learning in JAX. Records of the !mmortal Data Scientist. https://tahabouhsine.com/blog/organizing-randomness-jax/
BibTeX
@misc{bouhsine2026organizingrandomnessjax,
author = {Bouhsine, Taha},
title = {Organizing Randomness: Contrastive Learning in JAX},
year = {2026},
month = {may},
howpublished = {\url{https://tahabouhsine.com/blog/organizing-randomness-jax/}},
note = {Blog post, Records of the !mmortal Data Scientist}
}References
- (2006). Dimensionality Reduction by Learning an Invariant Mapping. CVPR 2006.
- (2015). FaceNet: A Unified Embedding for Face Recognition and Clustering. CVPR 2015.arXiv:1503.03832
- (2018). Representation Learning with Contrastive Predictive Coding. arXiv:1807.03748
- (2020). A Simple Framework for Contrastive Learning of Visual Representations (SimCLR). ICML 2020.arXiv:2002.05709
- (2020). Supervised Contrastive Learning. NeurIPS 2020.arXiv:2004.11362
- (2020). Understanding Contrastive Representation Learning Through Alignment and Uniformity on the Hypersphere. ICML 2020.arXiv:2005.10242
- (2021). Learning Transferable Visual Models From Natural Language Supervision (CLIP). ICML 2021.arXiv:2103.00020
- (2023). Sigmoid Loss for Language Image Pre-Training (SigLIP). ICCV 2023.arXiv:2303.15343